# java.util : The Collections Framework
This chapter begins our examination of java.util. This important package contains a large assortment of classes and interfaces that support a broad range of functionality. For example, java.util has classes that generate pseudorandom numbers, manage date and time, support events, manipulate sets of bits, tokenize strings, and handle formatted data. The java.util package also contains one of Java’s most powerful subsystems: the Collections Framework. The Collections Framework is a sophisticated hierarchy of interfaces and classes that provide state-of-the-art technology for managing groups of objects. It merits close attention by all programmers. Beginning with JDK 9, java.util is part of the java.base module.
Because java.util contains a wide array of functionality, it is quite large. Here is a list of its top-level classes:
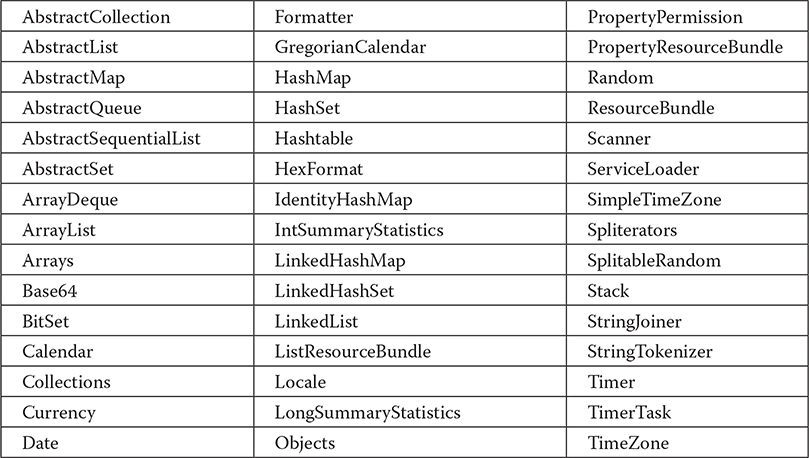
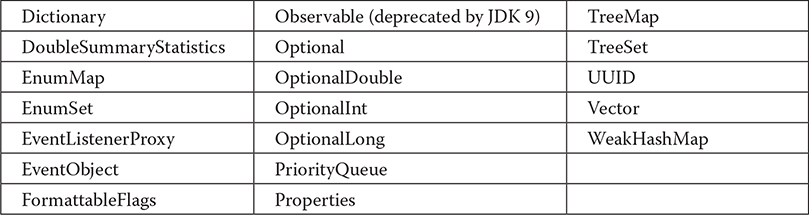
The interfaces defined by java.util are shown next:
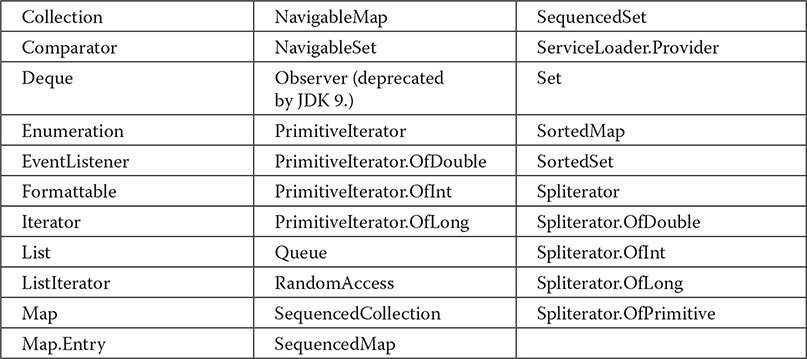
Because of its size, the description of java.util is broken into two chapters. This chapter examines those members of java.util that are part of the Collections Framework. Chapter 21 discusses its other classes and interfaces.
# Collections Overview
The Java Collections Framework standardizes the way in which groups of objects are handled by your programs. Collections were not part of the original Java release but were added by J2SE 1.2. Prior to the Collections Framework, Java provided ad hoc classes such as Dictionary, Vector, Stack, and Properties to store and manipulate groups of objects. Although these classes were quite useful, they lacked a central, unifying theme. The way that you used Vector was different from the way that you used Properties, for example. Also, this early, ad hoc approach was not designed to be easily extended or adapted. Collections were an answer to these (and other) problems.
The Collections Framework was designed to meet several goals. First, the framework had to be high-performance. The implementations for the fundamental collections (dynamic arrays, linked lists, trees, and hash tables) are highly efficient. You seldom, if ever, need to code one of these “data engines” manually. Second, the framework had to allow different types of collections to work in a similar manner and with a high degree of interoperability. Third, extending and/or adapting a collection had to be easy. Toward this end, the entire Collections Framework is built upon a set of standard interfaces. Several standard implementations (such as LinkedList, HashSet, and TreeSet) of these interfaces are provided that you may use as-is. You may also implement your own collection, if you choose. Various special-purpose implementations are created for your convenience, and some partial implementations are provided that make creating your own collection class easier. Finally, mechanisms were added that allow the integration of standard arrays into the Collections Framework.
Algorithms are another important part of the collection mechanism. Algorithms operate on collections and are defined as static methods within the Collections class. Thus, they are available for all collections. Each collection class need not implement its own versions. The algorithms provide a standard means of manipulating collections.
Another item closely associated with the Collections Framework is the Iterator interface. An iterator offers a general-purpose, standardized way of accessing the elements within a collection, one at a time. Thus, an iterator provides a means of enumerating the contents of a collection. Because each collection provides an iterator, the elements of any collection class can be accessed through the methods defined by Iterator. Thus, with only small changes, the code that cycles through a set can also be used to cycle through a list, for example.
JDK 8 added another type of iterator called a spliterator. In brief, spliterators are iterators that provide support for parallel iteration. The interfaces that support spliterators are Spliterator and several nested interfaces that support primitive types. Also available are iterator interfaces designed for use with primitive types, such as PrimitiveIterator and PrimitiveIterator.OfDouble.
In addition to collections, the framework defines several map interfaces and classes. Maps store key/value pairs. Although maps are part of the Collections Framework, they are not “collections” in the strict use of the term. You can, however, obtain a collection-view of a map. Such a view contains the elements from the map stored in a collection. Thus, you can process the contents of a map as a collection, if you choose.
JDK 21 further expands on the utility of the Collections Framework by formalizing the idea of the order in which you process elements in collections and maps, known as the encounter order. This order is important when you are looping through or iterating over the elements of such a collection. This idea is encapsulated in the form of the new SequencedCollection, SequencedSet, and SequencedMap interfaces and is implemented in those collections that have an inherent ordering in their elements.
The collection mechanism was retrofitted to some of the original classes defined by java.util so that they too could be integrated into the new system. It is important to understand that although the addition of collections altered the architecture of many of the original utility classes, it did not cause the deprecation of any. Collections simply provide a better way of doing several things.
NOTE If you are familiar with C++, then you will find it helpful to know that the Java collections technology is similar in spirit to the Standard Template Library (STL) defined by C++. What C++ calls a container, Java calls a collection. However, there are significant differences between the Collections Framework and the STL. It is important to not jump to conclusions.
# The Collection Interfaces
The Collections Framework defines several core interfaces. This section provides an overview of each interface. Beginning with the collection interfaces is necessary because they determine the fundamental nature of the collection classes. Put differently, the concrete classes simply provide different implementations of the standard interfaces. The interfaces that underpin collections are summarized in the following table:
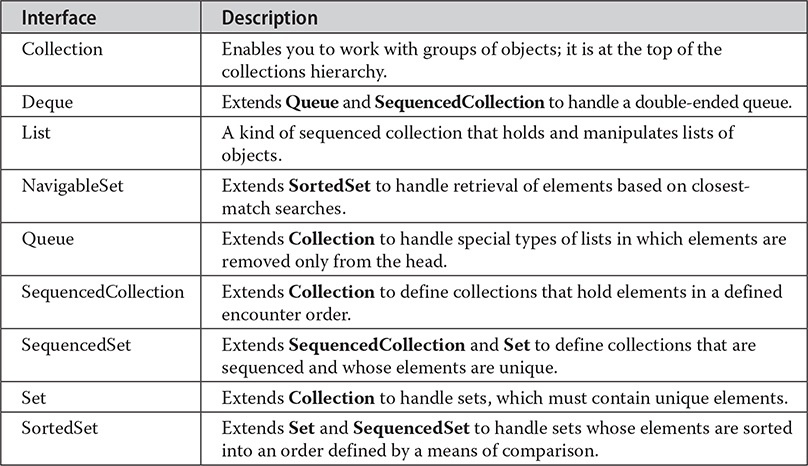
In addition to the collection interfaces, collections also use the Comparator, RandomAccess, Iterator, ListIterator, and Spliterator interfaces, which are described in depth later in this chapter. Briefly, Comparator defines how two objects are compared; Iterator, ListIterator, and Spliterator enumerate the objects within a collection. By implementing RandomAccess, a list indicates that it supports efficient, random access to its elements.
To provide the greatest flexibility in their use, the collection interfaces allow some methods to be optional. The optional methods enable you to modify the contents of a collection. Collections that support these methods are called modifiable. Collections that do not allow their contents to be changed are called unmodifiable. If an attempt is made to use one of these methods on an unmodifiable collection, an UnsupportedOperationException is thrown. All the built-in collections are modifiable.
The following sections examine the collection interfaces.
# The Collection Interface
The Collection interface is the foundation upon which the Collections Framework is built because it must be implemented by any class that defines a collection. Collection is a generic interface that has this declaration:
interface Collection<E>
Here, E specifies the type of objects that the collection will hold. Collection extends the Iterable interface. This means that all collections can be cycled through by use of the for-each style for loop. (Recall that only classes that implement Iterable can be cycled through by the for.)
Collection declares the core methods that all collections will have. These methods are summarized in Table 20-1. Because all collections implement Collection, familiarity with its methods is necessary for a clear understanding of the framework. Several of these methods can throw an UnsupportedOperationException. As explained, this occurs if a collection cannot be modified. A ClassCastException is generated when one object is incompatible with another, such as when an attempt is made to add an incompatible object to a collection. A NullPointerException is thrown if an attempt is made to store a null object and null elements are not allowed in the collection. An IllegalArgumentException is thrown if an invalid argument is used. An IllegalStateException is thrown if an attempt is made to add an element to a fixed-length collection that is full.
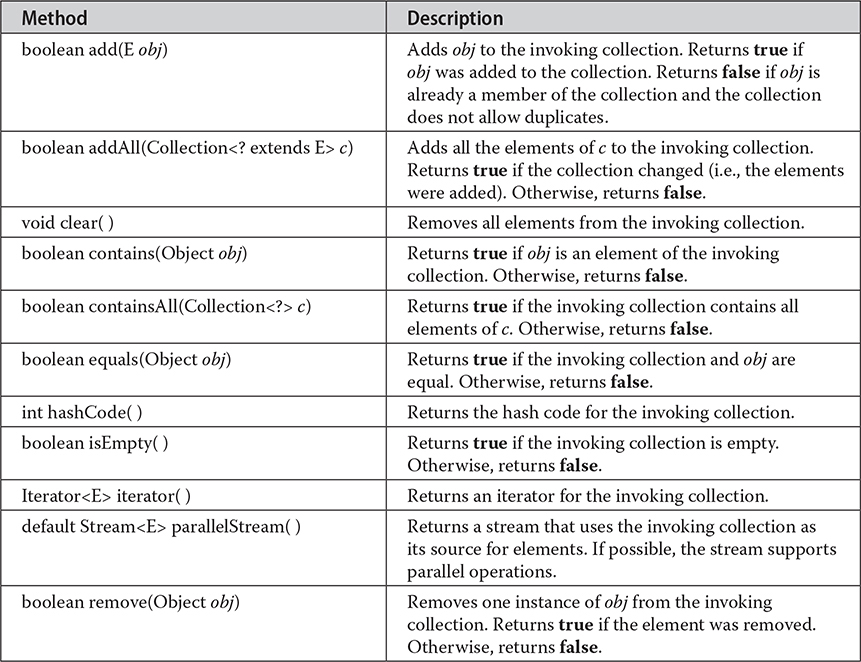
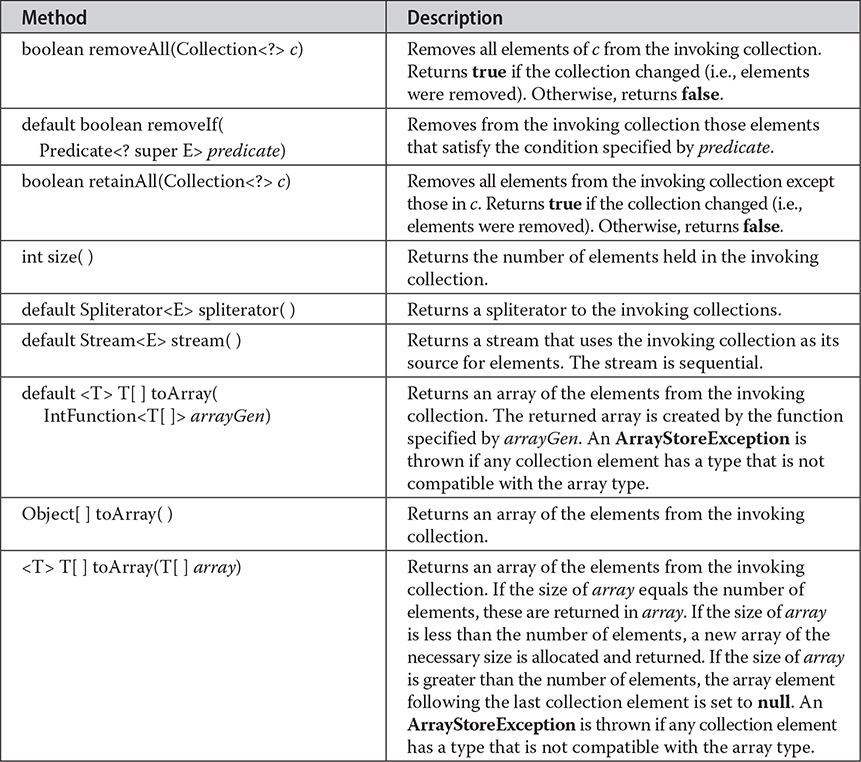
Table 20-1 The Methods Declared by Collection
Objects are added to a collection by calling add(). Notice that add() takes an argument of type E, which means that objects added to a collection must be compatible with the type of data expected by the collection. You can add the entire contents of one collection to another by calling addAll().
You can remove an object by using remove(). To remove a group of objects, call removeAll(). You can remove all elements except those of a specified group by calling retainAll(). To remove an element only if it satisifies some condition, you can use removeIf(). To empty a collection, call clear().
You can determine whether a collection contains a specific object by calling contains(). To determine whether one collection contains all the members of another, call containsAll(). You can determine when a collection is empty by calling isEmpty(). The number of elements currently held in a collection can be determined by calling size().
The toArray() methods return an array that contains the elements stored in the collection. The first returns an array of Object. The second returns an array of elements that have the same type as the array specified as a parameter. Normally, the second form is more convenient because it returns the desired array type. Beginning with JDK 11, a third form has been added that lets you specify a function that obtains the array. These methods are more important than they might at first seem. Often, processing the contents of a collection by using array-like syntax is advantageous. By providing a pathway between collections and arrays, you can have the best of both worlds.
Two collections can be compared for equality by calling equals(). The precise meaning of “equality” may differ from collection to collection. For example, you can implement equals() so that it compares the values of elements stored in the collection. Alternatively, equals() can compare references to those elements.
Another important method is iterator(), which returns an iterator to a collection. The spliterator() method returns a spliterator to the collection. Iterators are frequently used when working with collections. Finally, the stream() and parallelStream() methods return a Stream that uses the collection as a source of elements. (See Chapter 30 for a detailed discussion of the Stream interface.)
# The SequencedCollection Interface
Introduced in JDK 21, the SequencedCollection interface extends Collection and defines a special kind of collection that has an encounter order. This is a short way of saying that a SequencedCollection has a well-defined order in which you can process the elements, from one end of the collection to the other, such as when you use a for loop or an Iterator. SequencedCollection is a generic interface that has the declaration
interface SequencedCollection<E>
where E specifies the type of the objects this SequencedCollection will hold.
In addition to the methods of the Collection interface, SequencedCollection defines several methods that allow access and modifications to the first and last objects it holds as well as provide a reversed version of the collection, wherein the encounter order is backwards relative to the original collection. The methods of the SequencedCollection interface are shown in Table 20-2.
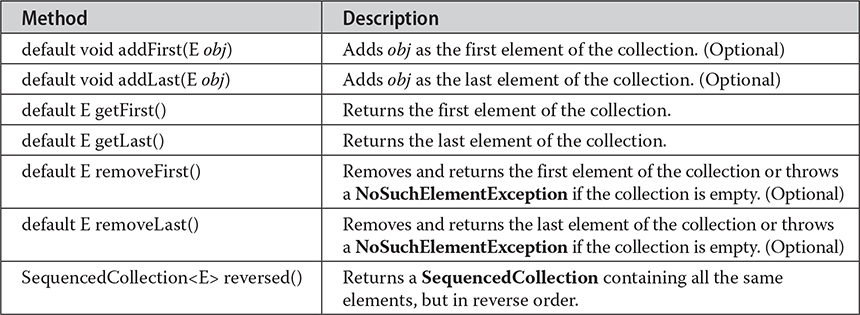
Table 20-2 The API Methods of SequencedCollection
Just as with the methods on its parent interface, the methods that add and remove objects from a SequencedCollection, such as addFirst(), are optional. That means that if the collection represented as a SequencedCollection is not able to be modified (we shall see later that there are such “read-only” implementations of collections), these methods will throw an UnsupportedOperationException. Similarly, either of the SequencedCollection methods that remove objects from the collection, such as removeLast(), are called when the collection doesn’t contain any objects; the result will be a NoSuchElementException. The reversed() method is very convenient if you want to loop or iterate backwards over a SequencedCollection. However, depending on the collection class implementing interface SequencedCollection, the reversed SequencedCollection obtained by calling this method may or may not change if you later modify the original collection on which you called reversed().
# The List Interface
The List interface extends SequencedCollection and declares the behavior of a collection that allows precise control over where in the sequence of objects an element can be placed. Elements can be inserted or accessed by their position in the list, using a zero-based index. A list may contain duplicate elements. List is a generic interface that has this declaration:
interface List<E>
Here, E specifies the type of objects that the list will hold.
In addition to the methods defined by SequencedCollection, List defines some of its own, which are summarized in Table 20-3. Note again that several of these methods will throw an UnsupportedOperationException if the list cannot be modified, and a ClassCastException is generated when one object is incompatible with another, such as when an attempt is made to add an incompatible object to a list. Also, several methods will throw an IndexOutOfBoundsException if an invalid index is used. A NullPointerException is thrown if an attempt is made to store a null object and null elements are not allowed in the list. An IllegalArgumentException is thrown if an invalid argument is used.
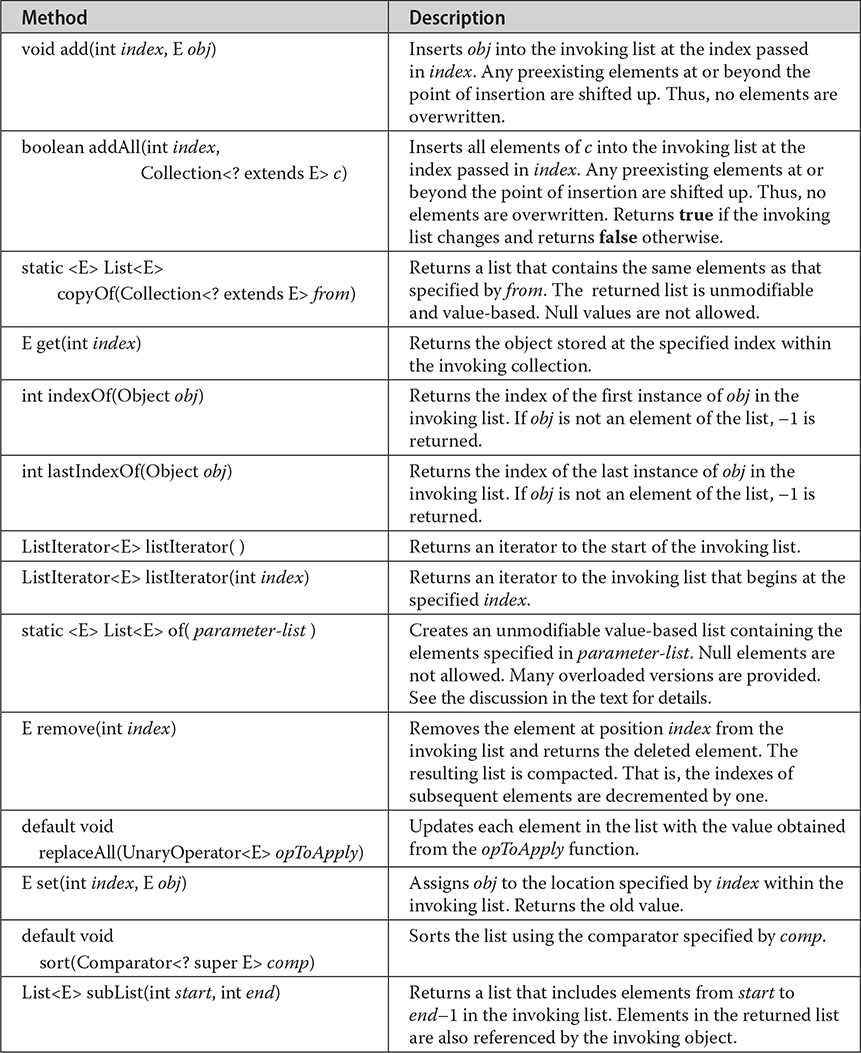
Table 20-3 The Methods Declared by List
To the versions of add() and addAll() defined by Collection, List adds the methods add(int, E) and addAll(int, Collection). These methods insert elements at the specified index. Also, the semantics of add(E) and addAll(Collection) defined by Collection are changed by List so that they add elements to the end of the list. You can modify each element in the collection by using replaceAll().
To obtain the object stored at a specific location, call get() with the index of the object. To assign a value to an element in the list, call set(), specifying the index of the object to be changed. To find the index of an object, use indexOf() or lastIndexOf().
You can obtain a sublist of a list by calling subList(), specifying the beginning and ending indexes of the sublist. As you can imagine, subList() makes list processing quite convenient. One way to sort a list is with the sort() method defined by List.
Beginning with JDK 9, List includes the of() factory method, which has a number of overloads. Each version returns an unmodifiable, value-based collection that is comprised of the arguments that it is passed. The primary purpose of of() is to provide a convenient, efficient way to create a small List collection. There are 12 overloads of of(). One takes no arguments and creates an empty list. It is shown here:
static <E> List<E> of()
Ten overloads take from 1 to 10 arguments and create a list that contains the specified elements. They are shown here:
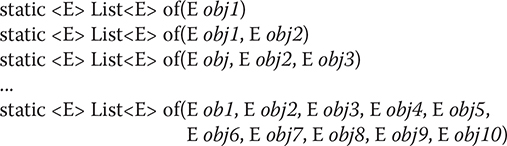
The final of() overload specifies a varargs parameter that takes an arbitrary number of elements or an array of elements. It is shown here:
static <E> List<E> of(E ... objs)
For all versions, null elements are not allowed. In all cases, the List implementation is unspecified.
# The Set Interface
The Set interface defines a set. It extends Collection and specifies the behavior of a collection that does not allow duplicate elements. Therefore, the add() method returns false if an attempt is made to add duplicate elements to a set. With two exceptions, it does not specify any additional methods of its own. Set is a generic interface that has this declaration:
interface Set<E>
Here, E specifies the type of objects that the set will hold.
Beginning with JDK 9, Set includes the of() factory method, which has a number of overloads. Each version returns an unmodifiable, value-based collection that is comprised of the arguments that it is passed. The primary purpose of of() is to provide a convenient, efficient way to create a small Set collection. There are 12 overloads of of(). One takes no arguments and creates an empty set. It is shown here:
static <E> Set<E> of()
Ten overloads take from 1 to 10 arguments and create a list that contains the specified elements. They are shown here:
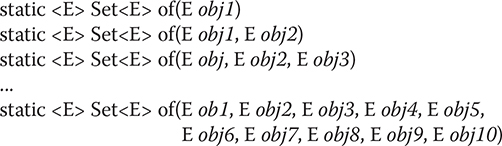
The final of() overload specifies a varargs parameter that takes an arbitrary number of elements or an array of elements. It is shown here:
static <E> Set<E> of(E ... objs)
For all versions, null elements are not allowed. In all cases, the Set implementation is unspecified.
Beginning with JDK 10, Set includes the static copyOf() method shown here:
static <E> Set<E> copyOf(Collection <? extends E> from)
It returns a set that contains the same elements as from. Null values are not allowed. The returned set is unmodifiable and value-based.
# The SequencedSet Interface
The SequencedSet interface, introduced in JDK 21, extends both Set and SequencedCollection and so inherits the behaviors of both of those types of collections. In other words, a SequencedSet is a special kind of collection with unique elements and with a well-defined order in which you can process the elements from one end of the collection to the other. SequencedSet is a generic interface that has this declaration:
interface SequencedSet<E>
Here, E specifies the type of objects this SequencedSet will hold.
The SequencedSet interface defines only one method over those it inherits. It overrides the reversed() method it inherits from SequencedCollection. It is shown here:
SequencedSet<E> reversed()
You can see that instead of returning just a SequencedCollection, it returns the more special SequencedSet, which, after all, it should: a special set with an order that has been reversed is still a special set with an order!
# The SortedSet Interface
The SortedSet interface extends SequencedSet and declares the behavior of a set that has a well-defined algorithm it uses to order its elements in ascending order. SortedSet is a generic interface that has this declaration:
interface SortedSet<E>
Here, E specifies the type of objects that the set will hold.
In addition to those methods provided by Set, the SortedSet interface declares the methods summarized in Table 20-4. Several methods throw a NoSuchElementException when no items are contained in the invoking set. A ClassCastException is thrown when an object is incompatible with the elements in a set. A NullPointerException is thrown if an attempt is made to use a null object and null is not allowed in the set. An IllegalArgumentException is thrown if an invalid argument is used.
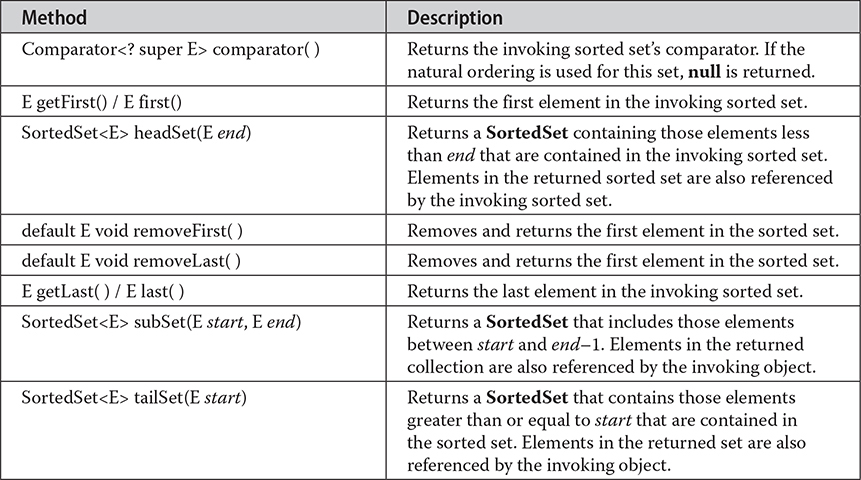
Table 20-4 Useful Methods Declared by SortedSet
SortedSet defines several methods that make set processing more convenient. To obtain the first object in the set, call getFirst(). To get the last element, use getLast(). You can obtain a subset of a sorted set by calling subSet(), specifying the first and last object in the set. If you need the subset that starts with the first element in the set, use headSet(). If you want the subset that ends the set, use tailSet().
Because SortedSet inherits from SequencedSet, it also inherits its parent interface’s methods to add elements from the start and end of the collection, namely the methods addFirst() and addLast(). But in a SortedSet, the order of the elements is always defined by its Comparator. So it doesn’t make sense to try to add or remove elements. For this reason, those methods throw an UnsupportedOperationException.
NOTE Note on sequenced versus sorted: In the collections framework, the idea of being sequenced is used to mean that the elements in a collection are arranged in a given order that does not change unless the collection is modified. This could be simply the order in which the elements were first added. The idea of a collection being sorted is stronger than sequenced: it means the collection is not only sequenced but is sequenced according to a given algorithm defined by its Comparator. If more elements are added to a sorted collection, they are put into position according to the comparator.
# The NavigableSet Interface
The NavigableSet interface extends SortedSet and declares the behavior of a collection that supports the retrieval of elements based on the closest match to a given value or values. NavigableSet is a generic interface that has this declaration:
interface NavigableSet<E>
Here, E specifies the type of objects that the set will hold. In addition to the methods that it inherits from SortedSet, NavigableSet adds those summarized in Table 20-5. A ClassCastException is thrown when an object is incompatible with the elements in the set. A NullPointerException is thrown if an attempt is made to use a null object and null is not allowed in the set. An IllegalArgumentException is thrown if an invalid argument is used.
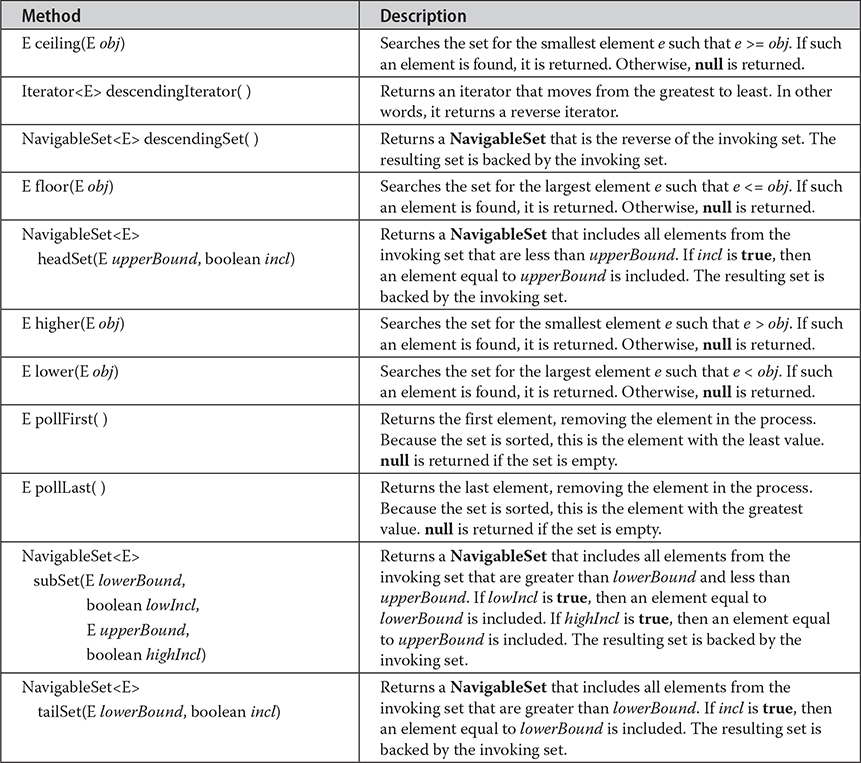
Table 20-5 The Methods Declared by NavigableSet
# The Queue Interface
The Queue interface extends Collection and declares the behavior of a queue, which is often a first-in, first-out list. However, there are types of queues in which the ordering is based upon other criteria. Queue is a generic interface that has this declaration:
interface Queue<E>
Here, E specifies the type of objects that the queue will hold. The methods declared by Queue are shown in Table 20-6.

Table 20-6 The Methods Declared by Queue
Several methods throw a ClassCastException when an object is incompatible with the elements in the queue. A NullPointerException is thrown if an attempt is made to store a null object and null elements are not allowed in the queue. An IllegalArgumentException is thrown if an invalid argument is used. An IllegalStateException is thrown if an attempt is made to add an element to a fixed-length queue that is full. A NoSuchElementException is thrown if an attempt is made to remove an element from an empty queue.
Despite its simplicity, Queue offers several points of interest. First, elements can only be removed from the head of the queue. Second, there are two methods that obtain and remove elements: poll() and remove(). The difference between them is that poll() returns null if the queue is empty, but remove() throws an exception. Third, there are two methods, element() and peek(), that obtain but don’t remove the element at the head of the queue. They differ only in that element() throws an exception if the queue is empty, but peek() returns null. Finally, notice that offer() only attempts to add an element to a queue. Because some queues have a fixed length and might be full, offer() can fail.
# The Deque Interface
The Deque interface extends Queue and SequencedCollection and so declares the behavior of a double-ended queue. Double-ended queues can function as standard, first-in, first-out queues or as last-in, first-out stacks. Deque is a generic interface that has this declaration:
interface Deque<E>
Here, E specifies the type of objects that the deque will hold. In addition to the methods that it inherits from Queue and SequencedCollection, Deque adds those methods summarized in Table 20-7. Several methods throw a ClassCastException when an object is incompatible with the elements in the deque. A NullPointerException is thrown if an attempt is made to store a null object and null elements are not allowed in the deque. An IllegalArgumentException is thrown if an invalid argument is used. An IllegalStateException is thrown if an attempt is made to add an element to a fixed-length deque that is full. A NoSuchElementException is thrown if an attempt is made to remove an element from an empty deque.
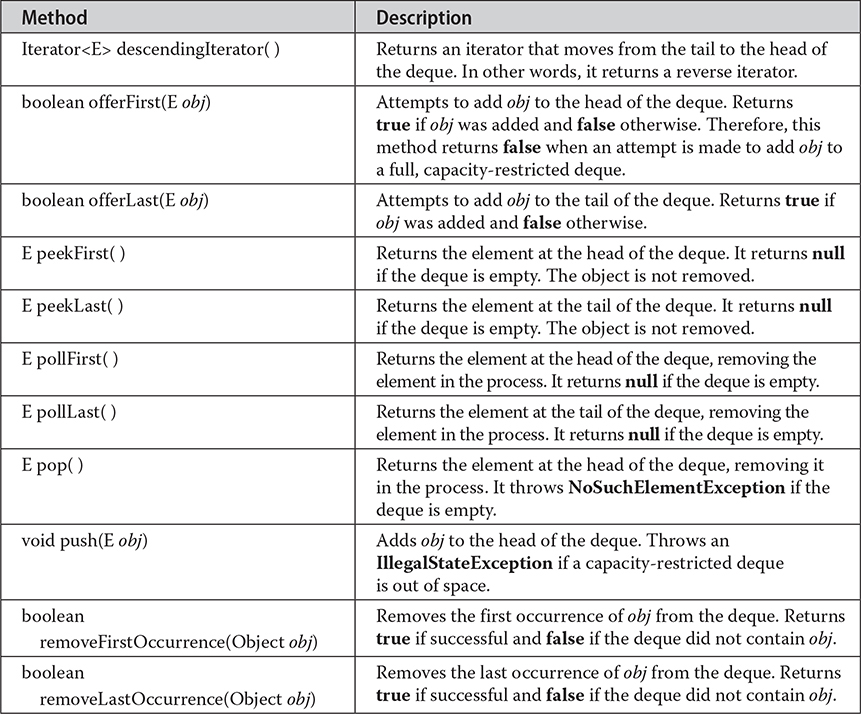
Table 20-7 The Methods Declared by Deque
Notice that Deque includes the methods push() and pop(). These methods enable a Deque to function as a stack. Also, notice the descendingIterator() method. It returns an iterator that returns elements in reverse order. In other words, it returns an iterator that moves from the end of the collection to the start. The reversed() method Deque since JDK 21, by virtue of its inheritance from SequencedCollection, serves a similar purpose, except it returns a Deque object instead of an Iterator. For traversing elements in large Deque collections, using the Iterator obtained by calling descendingIterator() may be more efficient. A Deque implementation can be capacity-restricted, which means that only a limited number of elements can be added to the deque. When this is the case, an attempt to add an element to the deque can fail. Deque allows you to handle such a failure in two ways. First, methods such as addFirst() and addLast() throw an IllegalStateException if a capacity-restricted deque is full. Second, methods such as offerFirst() and offerLast() return false if the element cannot be added.
# The Collection Classes
Now that you are familiar with the collection interfaces, you are ready to examine the standard classes that implement them. Some of the classes provide full implementations that can be used as-is. Others are abstract, providing skeletal implementations that are used as starting points for creating concrete collections. As a general rule, the collection classes are not synchronized, but as you will see later in this chapter, it is possible to obtain synchronized versions.
The core collection classes are summarized in the following table:
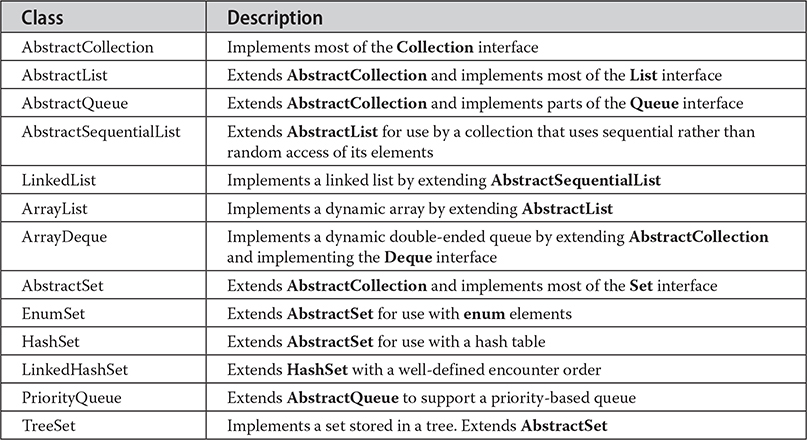
The following sections examine the concrete collection classes and illustrate their use.
NOTE In addition to the collection classes, several legacy classes, such as Vector, Stack, and Hashtable, have been reengineered to support collections. These are examined later in this chapter.
# The ArrayList Class
The ArrayList class extends AbstractList and implements the List interface. ArrayList is a generic class that has this declaration:
class ArrayList<E>
Here, E specifies the type of objects that the list will hold.
ArrayList supports dynamic arrays that can grow as needed. In Java, standard arrays are of a fixed length. After arrays are created, they cannot grow or shrink, which means that you must know in advance how many elements an array will hold. But, sometimes, you may not know until run time precisely how large an array you need. To handle this situation, the Collections Framework defines ArrayList. In essence, an ArrayList is a variable-length array of object references. That is, an ArrayList can dynamically increase or decrease in size. Array lists are created with an initial size. When this size is exceeded, the collection is automatically enlarged. When objects are removed, the array can be shrunk.
NOTE Dynamic arrays are also supported by the legacy class Vector, which is described later in this chapter.
ArrayList has the constructors shown here:
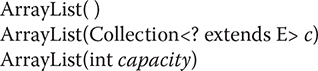
The first constructor builds an empty array list. The second constructor builds an array list that is initialized with the elements of the collection c. The third constructor builds an array list that has the specified initial capacity. The capacity is the size of the underlying array that is used to store the elements. The capacity grows automatically as elements are added to an array list.
The following program shows a simple use of ArrayList. An array list is created for objects of type String, and then several strings are added to it. (Recall that a quoted string is translated into a String object.) The list is then displayed. Some of the elements are removed and the list is displayed again.

The output from this program is shown here:

Notice that a1 starts out empty and grows as elements are added to it. When elements are removed, its size is reduced.
In the preceding example, the contents of a collection are displayed using the default conversion provided by toString(), which was inherited from AbstractCollection. Although it is sufficient for short, sample programs, you seldom use this method to display the contents of a real-world collection. Usually, you provide your own output routines. But, for the next few examples, the default output created by toString() is sufficient.
Although the capacity of an ArrayList object increases automatically as objects are stored in it, you can increase the capacity of an ArrayList object manually by calling ensureCapacity(). You might want to do this if you know in advance that you will be storing many more items in the collection than it can currently hold. By increasing its capacity once, at the start, you can prevent several reallocations later. Because reallocations are costly in terms of time, preventing unnecessary ones improves performance. The signature for ensureCapacity() is shown here:
void ensureCapacity(int cap)
Here, cap specifies the new minimum capacity of the collection.
Conversely, if you want to reduce the size of the array that underlies an ArrayList object so that it is precisely as large as the number of items that it is currently holding, call trimToSize(), shown here:
void trimToSize()
Finally, you can see that, through the methods of the List interface it implements, the ArrayList provides a variety of ways to add and remove elements precisely at the position you need and even produce a list in reverse order with the reversed() method.
# Obtaining an Array from an ArrayList
When working with ArrayList, you will sometimes want to obtain an actual array that contains the contents of the list. You can do this by calling toArray(), which is defined by Collection. Several reasons exist why you might want to convert a collection into an array, such as:
• To obtain faster processing times for certain operations
• To pass an array to a method that is not overloaded to accept a collection
• To integrate collection-based code with legacy code that does not understand collections
Whatever the reason, converting an ArrayList to an array is a trivial matter.
As explained earlier, there are three versions of toArray(), which are shown again here for your convenience:
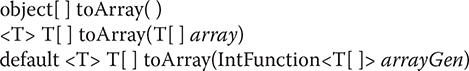
The first returns an array of Object. The second and third forms return an array of elements that have the same type as T. Here, we will use the second form because of its convenience. The following program shows it in action:

The output from the program is shown here:
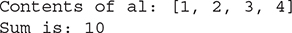
The program begins by creating a collection of integers. Next, toArray() is called, and it obtains an array of Integers. Then, the contents of that array are summed by use of a for-each style for loop.
There is something else of interest in this program. As you know, collections can store only references, not values of primitive types. However, autoboxing makes it possible to pass values of type int to add() without having to manually wrap them within an Integer, as the program shows. Autoboxing causes them to be automatically wrapped. In this way, autoboxing significantly improves the ease with which collections can be used to store primitive values.
# The LinkedList Class
The LinkedList class extends AbstractSequentialList and implements the List, Deque, and Queue interfaces. It provides a linked-list data structure. LinkedList is a generic class that has this declaration:
class LinkedList<E>
Here, E specifies the type of objects that the list will hold. LinkedList has the two constructors shown here:
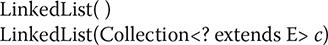
The first constructor builds an empty linked list. The second constructor builds a linked list that is initialized with the elements of the collection c.
Because LinkedList implements the Deque interface, you have access to the methods defined by Deque. For example, to add elements to the start of a list, you can use addFirst() or offerFirst(). To add elements to the end of the list, use addLast() or offerLast(). To obtain the first element, you can use getFirst() or peekFirst(). To obtain the last element, use getLast() or peekLast(). To remove the first element, use removeFirst() or pollFirst(). To remove the last element, use removeLast() or pollLast().
The following program illustrates LinkedList:


The output from this program is shown here:

Because LinkedList implements the List interface, calls to add(E) append items to the end of the list, as do calls to addLast(). To insert items at a specific location, use the add(int, E) form of add(), as illustrated by the call to add(1, "A2") in the example.
Notice how the third element in ll is changed by employing calls to get() and set(). To obtain the current value of an element, pass get() the index at which the element is stored. To assign a new value to that index, pass set() the index and its new value.
# The HashSet Class
HashSet extends AbstractSet and implements the Set interface. It creates a collection that uses a hash table for storage. HashSet is a generic class that has this declaration:
class HashSet<E>
Here, E specifies the type of objects that the set will hold.
As most readers likely know, a hash table stores information by using a mechanism called hashing. In hashing, the informational content of a key is used to determine a unique value, called its hash code. The hash code is then used as the index at which the data associated with the key is stored. The transformation of the key into its hash code is performed automatically—you never see the hash code itself. Also, your code can’t directly index the hash table. The advantage of hashing is that it allows the execution time of add(), contains(), remove(), and size() to remain constant even for large sets.
The following constructors are defined:

The first form constructs a default hash set. The second form initializes the hash set by using the elements of c. The third form initializes the capacity of the hash set to capacity. (The default capacity is 16.) The fourth form initializes both the capacity and the fill ratio (also called load factor) of the hash set from its arguments. The fill ratio must be between 0.0 and 1.0, and it determines how full the hash set can be before it is resized upward. Specifically, when the number of elements is greater than the capacity of the hash set multiplied by its fill ratio, the hash set is expanded. For constructors that do not take a fill ratio, 0.75 is used.
HashSet defines only one additional method, newHashSet(), added in JDK 19, beyond those provided by its superclasses and interfaces.
It is important to note that HashSet does not guarantee the order of its elements, because the process of hashing doesn’t usually lend itself to the creation of sorted sets. If you need sorted storage, then another collection, such as TreeSet, is a better choice.
Here is an example that demonstrates HashSet:

The following is the output from this program:
[Gamma, Eta, Alpha, Epsilon, Omega, Beta]
As explained, the elements are not stored in sorted order, and the precise output may vary.
# The LinkedHashSet Class
The LinkedHashSet class extends HashSet and adds only one method of its own, newLinkedHashSet(), beginning in JDK 19. It is a generic class that has this declaration:
class LinkedHashSet<E>
Here, E specifies the type of objects that the set will hold. Its constructors parallel those in HashSet.
LinkedHashSet maintains a linked list of the entries in the set, in the order in which they were inserted. This allows insertion-order iteration over the set. That is, when you’re cycling through a LinkedHashSet using an iterator, the elements will be returned in the order in which they were inserted. This is also the order in which they are contained in the string returned by toString() when called on a LinkedHashSet object. To see the effect of LinkedHashSet, try substituting LinkedHashSet for HashSet in the preceding program. The output will be
[Beta, Alpha, Eta, Gamma, Epsilon, Omega]
which is the order in which the elements were inserted.
Since JDK 21, LinkedHashSet implements the methods of the new SequencedSet interface, which allows easy addition and removal of elements at the start and end.
# The TreeSet Class
TreeSet extends AbstractSet and implements the NavigableSet interface. It creates a collection that uses a tree for storage. Objects are stored in sorted, ascending order. Access and retrieval times are quite fast, which makes TreeSet an excellent choice when storing large amounts of sorted information that must be found quickly.
TreeSet is a generic class that has this declaration:
class TreeSet<E>
Here, E specifies the type of objects that the set will hold.
TreeSet has the following constructors:

The first form constructs an empty tree set that will be sorted in ascending order according to the natural order of its elements. The second form builds a tree set that contains the elements of c. The third form constructs an empty tree set that will be sorted according to the comparator specified by comp. (Comparators are described later in this chapter.) The fourth form builds a tree set that contains the elements of ss.
Here is an example that demonstrates a TreeSet:

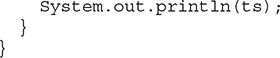
The output from this program is shown here:
[A, B, C, D, E, F]
As explained, because TreeSet stores its elements in a tree, they are automatically arranged in sorted order, as the output confirms.
Because TreeSet implements the NavigableSet interface, you can use the methods defined by NavigableSet to retrieve elements of a TreeSet. For example, assuming the preceding program, the following statement uses subSet() to obtain a subset of ts that contains the elements between C (inclusive) and F (exclusive). It then displays the resulting set.
System.out.println(ts.subSet("C", "F"));
The output from this statement is shown here:
[C, D, E]
You might want to experiment with the other methods defined by NavigableSet.
# The PriorityQueue Class
PriorityQueue extends AbstractQueue and implements the Queue interface. It creates a queue that is prioritized based on the queue’s comparator. PriorityQueue is a generic class that has this declaration:
class PriorityQueue<E>
Here, E specifies the type of objects stored in the queue. PriorityQueues are dynamic, growing as necessary.
PriorityQueue defines the seven constructors shown here:

The first constructor builds an empty queue. Its starting capacity is 11. The second constructor builds a queue that has the specified initial capacity. The third constructor specifies a comparator, and the fourth builds a queue with the specified capacity and comparator. The last three constructors create queues that are initialized with the elements of the collection passed in c. In all cases, the capacity grows automatically as elements are added.
If no comparator is specified when a PriorityQueue is constructed, then the default comparator for the type of data stored in the queue is used. The default comparator will order the queue in ascending order. Thus, the head of the queue will be the smallest value. However, by providing a custom comparator, you can specify a different ordering scheme. For example, when storing items that include a time stamp, you could prioritize the queue such that the oldest items are first in the queue.
You can obtain a reference to the comparator used by a PriorityQueue by calling its comparator() method, shown here:
Comparator<? super E> comparator()
It returns the comparator. If natural ordering is used for the invoking queue, null is returned.
One word of caution: Although you can iterate through a PriorityQueue using an iterator, the order of that iteration is undefined. To properly use a PriorityQueue, you must call methods such as offer() and poll(), which are defined by the Queue interface.
# The ArrayDeque Class
The ArrayDeque class extends AbstractCollection and implements the Deque interface. It adds no methods of its own. ArrayDeque creates a dynamic array and has no capacity restrictions. (The Deque interface supports implementations that restrict capacity but does not require such restrictions.) ArrayDeque is a generic class that has this declaration:
class ArrayDeque<E>
Here, E specifies the type of objects stored in the collection.
ArrayDeque defines the following constructors:
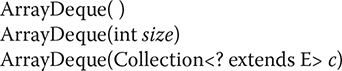
The first constructor builds an empty deque. Its starting capacity is 16. The second constructor builds a deque that has the specified initial capacity. The third constructor creates a deque that is initialized with the elements of the collection passed in c. In all cases, the capacity grows as needed to handle the elements added to the deque.
The following program demonstrates ArrayDeque by using it to create a stack:


The output is shown here:
Popping the stack: F E D B A
# The EnumSet Class
EnumSet extends AbstractSet and implements Set. It is specifically for use with elements of an enum type. It is a generic class that has this declaration:
class EnumSet<E extends Enum<E>>
Here, E specifies the elements. Notice that E must extend Enum<E>, which enforces the requirement that the elements must be of the specified enum type.
EnumSet defines no constructors. Instead, it uses the factory methods shown in Table 20-8 to create objects. All methods can throw NullPointerException. The copyOf() and range() methods can also throw IllegalArgumentException. Notice that the of() method is overloaded a number of times. This is in the interest of efficiency. Passing a known number of arguments can be faster than using a vararg parameter when the number of arguments is small.
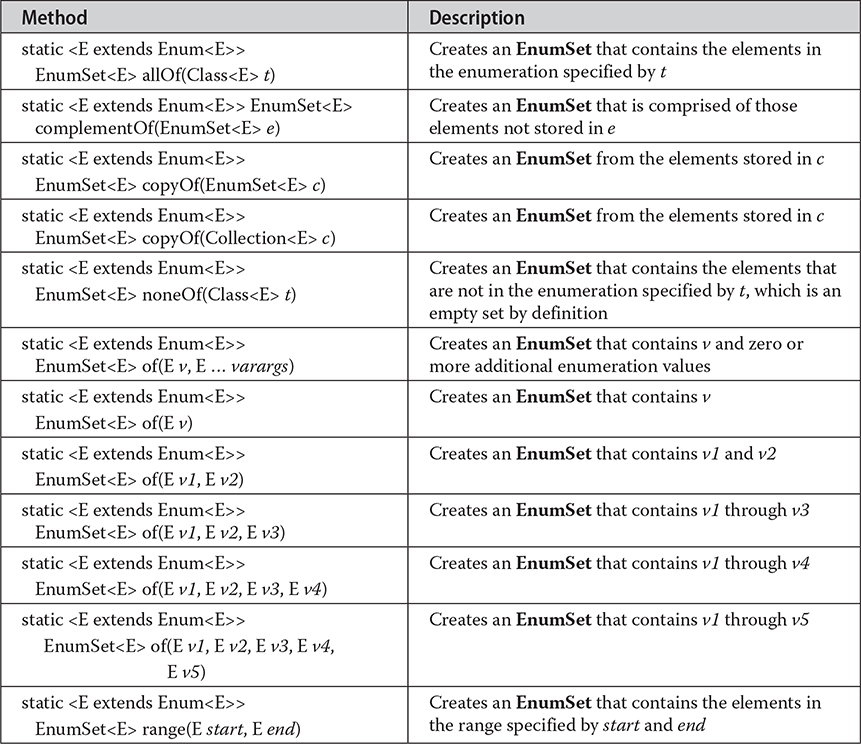
Table 20-8 The Methods Declared by EnumSet
# Accessing a Collection via an Iterator
Often, you will want to cycle through the elements in a collection. For example, you might want to display each element. One way to do this is to employ an iterator, which is an object that implements either the Iterator or the ListIterator interface. Iterator enables you to cycle through a collection, obtaining or removing elements. ListIterator extends Iterator to allow bidirectional traversal of a list, and the modification of elements. Iterator and ListIterator are generic interfaces, which are declared as shown here:
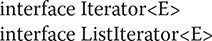
Here, E specifies the type of objects being iterated. The Iterator interface declares the methods shown in Table 20-9. The methods declared by ListIterator (along with those inherited from Iterator) are shown in Table 20-10. In both cases, operations that modify the underlying collection are optional. For example, remove() will throw UnsupportedOperationException when used with a read-only collection. Various other exceptions are possible.
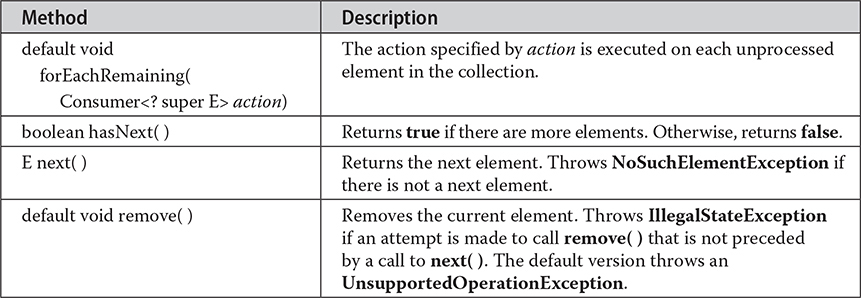
Table 20-9 The Methods Declared by Iterator
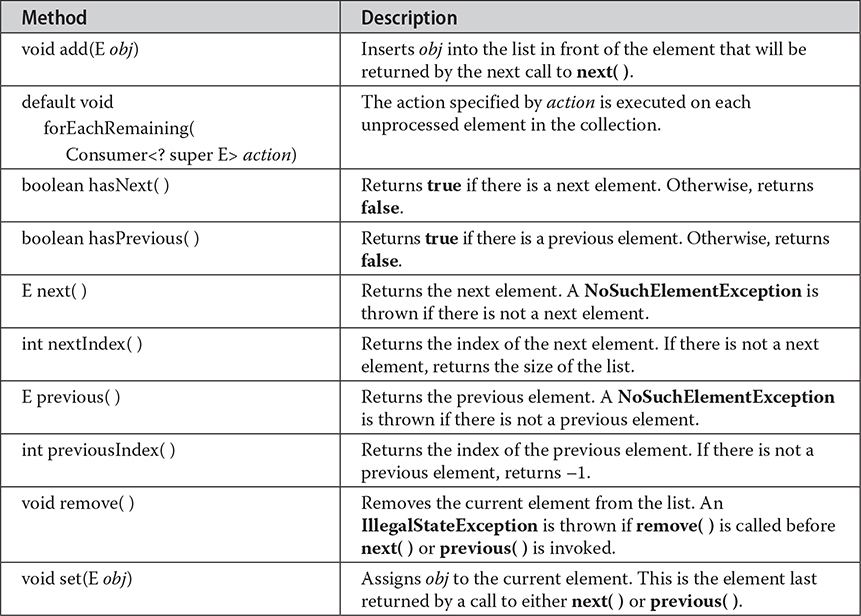
Table 20-10 The Methods Provided by ListIterator
NOTE You can also use a Spliterator to cycle through a collection. Spliterator works differently than does Iterator, and it is described later in this chapter.
# Using an Iterator
Before you can access a collection through an iterator, you must obtain one. Each of the collection classes provides an iterator() method that returns an iterator to the start of the collection. By using this iterator object, you can access each element in the collection, one element at a time. In general, to use an iterator to cycle through the contents of a collection, follow these steps:
Obtain an iterator to the start of the collection by calling the collection’s iterator() method.
Set up a loop that makes a call to hasNext(). Have the loop iterate as long as hasNext() returns true.
Within the loop, obtain each element by calling next().
For collections that implement List, you can also obtain an iterator by calling listIterator(). As explained, a list iterator gives you the ability to access the collection in either the forward or backward direction and lets you modify an element. Otherwise, ListIterator is used just like Iterator.
The following example implements these steps, demonstrating both the Iterator and ListIterator interfaces. It uses an ArrayList object, but the general principles apply to any type of collection. Of course, ListIterator is available only to those collections that implement the List interface.

The output is shown here:

Pay special attention to how the list is displayed in reverse. After the list is modified, litr points to the end of the list. (Remember, litr.hasNext() returns false when the end of the list has been reached.) To traverse the list in reverse, the program continues to use litr, but this time it checks to see whether it has a previous element. As long as it does, that element is obtained and displayed.
# The For-Each Alternative to Iterators
If you won’t be modifying the contents of a collection or obtaining elements in reverse order, then the for-each version of the for loop is often a more convenient alternative to cycling through a collection than is using an iterator. Recall that the for can cycle through any collection of objects that implement the Iterable interface. Because all of the collection classes implement this interface, they can all be operated upon by the for.
The following example uses a for loop to sum the contents of a collection:

The output from the program is shown here:
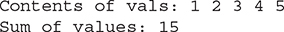
As you can see, the for loop is substantially shorter and simpler to use than the iterator-based approach. One limitation is that you can’t modify the contents of the collection during the for loop. In addition, you can also only cycle forward through a collection, though for those collections that implement SequencedCollection, like List and SortedSet, you can easily use reversed() to produce an Iterator with which you can use a for loop to cycle backwards through your collection.
# Spliterators
JDK 8 added another type of iterator called a spliterator that is defined by the Spliterator interface. A spliterator cycles through a sequence of elements, and in this regard, it is similar to the iterators just described. However, the techniques required to use it differ. Furthermore, it offers substantially more functionality than does either Iterator or ListIterator. Perhaps the most important aspect of Spliterator is its ability to provide support for parallel iteration of portions of the sequence. Thus, Spliterator supports parallel programming. (See Chapter 29 for information on concurrency and parallel programming.) However, you can use Spliterator even if you won’t be using parallel execution. One reason you might want to do so is because it offers a streamlined approach that combines the hasNext and next operations into one method.
Spliterator is a generic interface that is declared like this:
interface Spliterator<T>
Here, T is the type of elements being iterated. Spliterator declares the methods shown in Table 20-11.
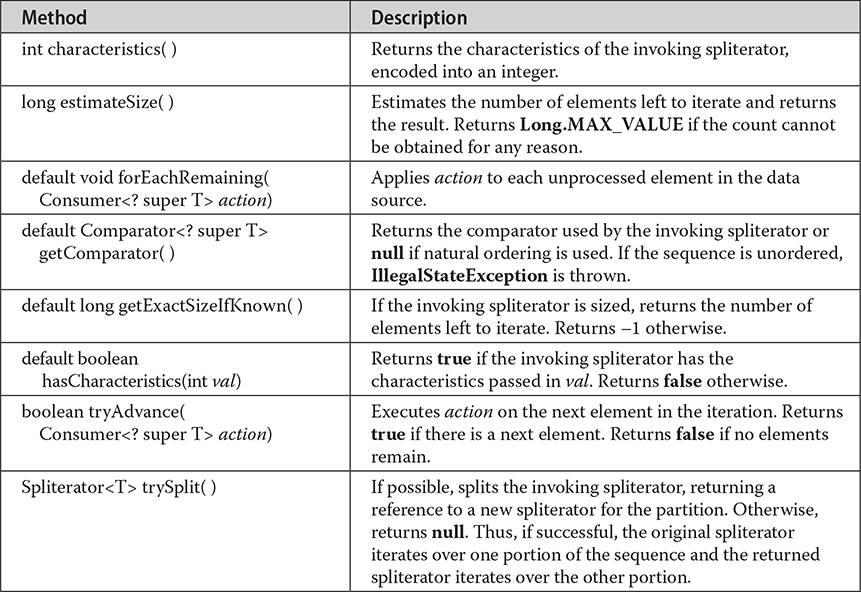
Table 20-11 The Methods Declared by Spliterator
Using Spliterator for basic iteration tasks is quite easy: simply call tryAdvance() until it returns false. If you will be applying the same action to each element in the sequence, forEachRemaining() offers a streamlined alternative. In both cases, the action that will occur with each iteration is defined by what the Consumer object does with each element. Consumer is a functional interface that applies an action to an object. It is a generic functional interface declared in java.util.function. (See Chapter 21 for information on java.util.function.) Consumer specifies only one abstract method, accept(), which is shown here:
void accept(T objRef)
In the case of tryAdvance(), each iteration passes the next element in the sequence to objRef. Often, the easiest way to implement Consumer is by use of a lambda expression.
The following program provides a simple example of Spliterator. Notice that the program demonstrates both tryAdvance() and forEachRemaining(). Also notice how these methods combine the actions of Iterator’s next() and hasNext() methods into a single call.



The output is shown here:

Although this program demonstrates the mechanics of using Spliterator, it does not reveal its full power. As mentioned, Spliterator’s maximum benefit is found in situations that involve parallel processing.
In Table 20-10, notice the methods characteristics() and hasCharacteristics(). Each Spliterator has a set of attributes, called characteristics, associated with it. These are defined by static int fields in Spliterator, such as SORTED, DISTINCT, SIZED, and IMMUTABLE, to name a few. You can obtain the characteristics by calling characteristics(). You can determine if a characteristic is present by calling hasCharacteristics(). Often, you won’t need to access a Spliterator’s characteristics, but in some cases, they can aid in creating efficient, resilient code.
NOTE For a further discussion of Spliterator, see Chapter 30, where it is used in the context of the stream API. For a discussion of lambda expressions, see Chapter 15. See Chapter 29 for a discussion of parallel programming and concurrency.
There are several nested subinterfaces of Spliterator designed for use with the primitive types double, int, and long. These are called Spliterator.OfDouble, Spliterator.OfInt, and Spliterator.OfLong. There is also a generalized version called Spliterator.OfPrimitive(), which offers additional flexibility and serves as a superinterface of the aforementioned ones.
# Storing User-Defined Classes in Collections
For the sake of simplicity, the foregoing examples have stored built-in objects, such as String and Integer, in a collection. Of course, collections are not limited to the storage of built-in objects. Quite the contrary. The power of collections is that they can store any type of object, including objects of classes that you create. For example, consider the following example, which uses a LinkedList to store mailing addresses:

The output from the program is shown here:

Aside from storing a user-defined class in a collection, another important thing to notice about the preceding program is that it is quite short. When you consider that it sets up a linked list that can store, retrieve, and process mailing addresses in about 50 lines of code, the power of the Collections Framework begins to become apparent. As most readers know, if all of this functionality had to be coded manually, the program would be several times longer. Collections offer off-the-shelf solutions to a wide variety of programming problems. You should use them whenever the situation presents itself.
# The RandomAccess Interface
The RandomAccess interface contains no members. However, by implementing this interface, a collection signals that it supports efficient random access to its elements. Although a collection might support random access, it might not do so efficiently. By checking for the RandomAccess interface, client code can determine at run time whether a collection is suitable for certain types of random access operations—especially as they apply to large collections. (You can use instanceof to determine if a class implements an interface.) RandomAccess is implemented by ArrayList and by the legacy Vector class, among others.
# Working with Maps
A map is an object that stores associations between keys and values, or key/value pairs. Given a key, you can find its value. Both keys and values are objects. The keys must be unique, but the values may be duplicated. Some maps can accept a null key and null values, and others cannot.
There is one key point about maps that is important to mention at the outset: they don’t implement the Iterable interface. This means that you cannot cycle through a map using a for-each style for loop. Furthermore, you can’t obtain an iterator to a map. However, as you will soon see, you can obtain a collection-view of a map, which does allow the use of either the for loop or an iterator.
# The Map Interfaces
Because the map interfaces define the character and nature of maps, this discussion of maps begins with them. The following interfaces support maps:
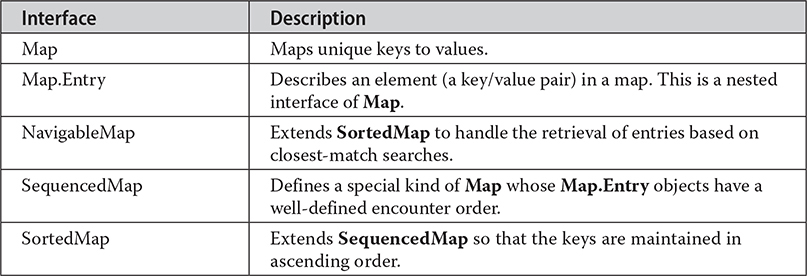
Each interface is examined next, in turn.
# The Map Interface
The Map interface maps unique keys to values. A key is an object that you use to retrieve a value at a later date. Given a key and a value, you can store the value in a Map object. After the value is stored, you can retrieve it by using its key. Map is generic and is declared as shown here:
interface Map<K, V>
Here, K specifies the type of keys, and V specifies the type of values.
The methods declared by Map are summarized in Table 20-12. Several methods throw a ClassCastException when an object is incompatible with the elements in a map. A NullPointerException is thrown if an attempt is made to use a null object and null is not allowed in the map. An UnsupportedOperationException is thrown when an attempt is made to change an unmodifiable map. An IllegalArgumentException is thrown if an invalid argument is used.
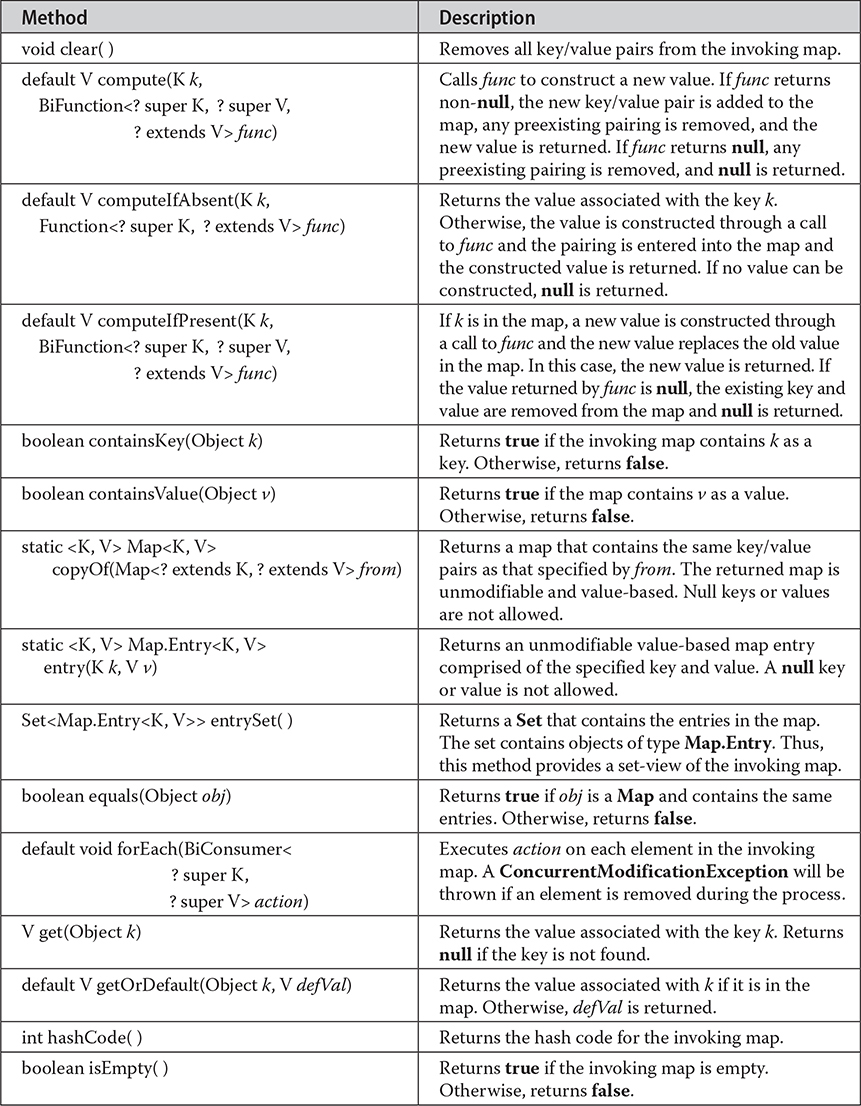


Table 20-12 The Methods Declared by Map
Maps revolve around two basic operations: get() and put(). To put a value into a map, use put(), specifying the key and the value. To obtain a value, call get(), passing the key as an argument. The value is returned.
As mentioned earlier, although part of the Collections Framework, maps are not, themselves, collections because they do not implement the Collection interface. However, you can obtain a collection-view of a map. To do this, you can use the entrySet() method. It returns a Set that contains the elements in the map. To obtain a collection-view of the keys, use keySet(). To get a collection-view of the values, use values(). For all three collection-views, the collection is backed by the map. Changing one affects the other. Collection-views are the means by which maps are integrated into the larger Collections Framework.
Beginning with JDK 9, Map includes the of() factory method, which has a number of overloads. Each version returns an unmodifiable, value-based map that is comprised of the arguments that it is passed. The primary purpose of of() is to provide a convenient, efficient way to create a small Map. There are 11 overloads of of(). One takes no arguments and creates an empty map. It is shown here:
static <K, V> Map<K, V> of()
Ten overloads take from 1 to 10 arguments and create a list that contains the specified elements. They are shown here:
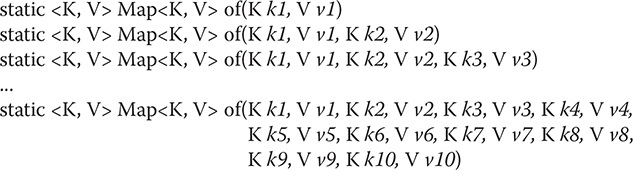
For all versions, null keys and/or values are not allowed. In all cases, the Map implementation is unspecified.
# The SequencedMap Interface
Introduced in JDK 21, the SequencedMap interface extends Map to define a special kind of map whose entries (key value pairs) have a well-defined encounter order. This is a short way of saying that SequencedMap objects have a well-defined order in which you can process the entries, such as when you use a for loop or an Iterator. SequencedMap is a generic interface that has this declaration:
interface SequencedMap<E>
Here, E specifies the type of objects this SequencedMap will hold.
In addition to the methods of the Map interface, SequencedMap defines several methods that allow access and modifications to its first and last entries as well as provide a reversed version of the itself, wherein the encounter order of the entries is reversed. The methods of the SequencedMap interface are shown in Table 20-13.
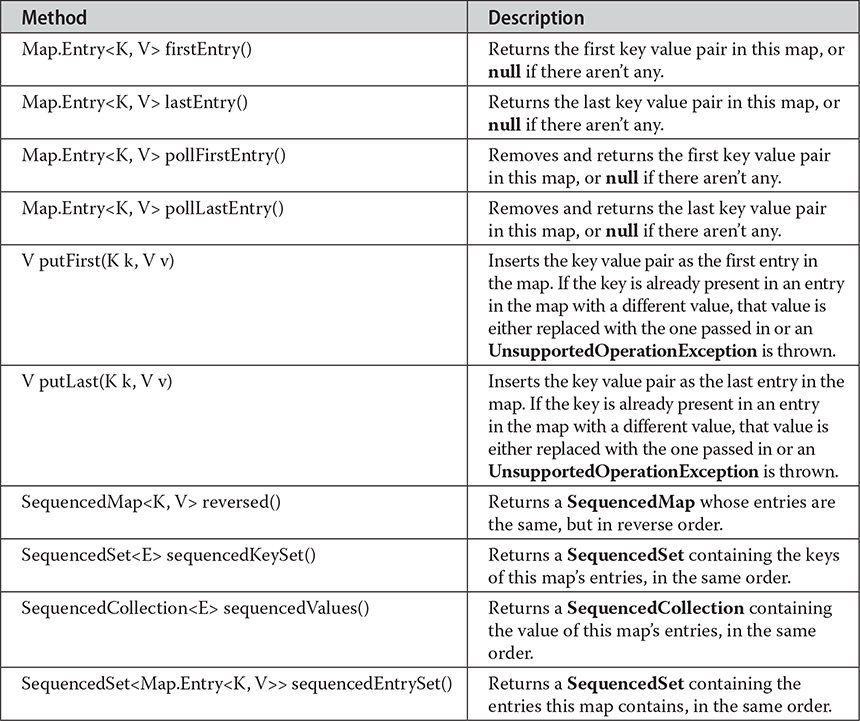
Table 20-13 The Methods Declared by SequencedMap
You can think of a SequencedMap as being similar to a SequencedCollection, but instead of applying to its elements, the encounter order of a SequencedMap applies to its entries. This allows for convenient manipulation of the addition of entries to the SequencedMap at the beginning or the end of the map using methods like putFirst() and pollLast(). You can use the sequenced collection representations of the keys, values, and entries as obtained when you call sequencedKeySet(), sequencedValues(), and sequencedEntrySet(), respectively. Finally, together with the reversed() method, which returns a map containing the same entries but in backwards encounter order, you can use Iterators and for loops to conveniently traverse all aspects of the SequencedMap’s contents in any direction you like.
# The SortedMap Interface
The SortedMap interface extends SequencedMap. It ensures that the entries are maintained in ascending order based on a well-defined sorting algorithm used to order the map’s keys. Note this is a stronger type of ordering than that defined by SequencedMap. A SequencedMap’s entries may be ordered simply in the order they were added, even in the case, for example, where its keys are integers with no particular numerical ordering applied. In sorting its keys with a particular Comparator object, a SortedMap always has a well-defined encounter order. SortedMap is generic and is declared as shown here:
interface SortedMap<K, V>
Here, K specifies the type of keys, and V specifies the type of values.
The methods added by SortedMap are summarized in Table 20-14. Several methods throw a NoSuchElementException when no items are in the invoking map. A ClassCastException is thrown when an object is incompatible with the elements in a map. A NullPointerException is thrown if an attempt is made to use a null object when null is not allowed in the map. An IllegalArgumentException is thrown if an invalid argument is used.
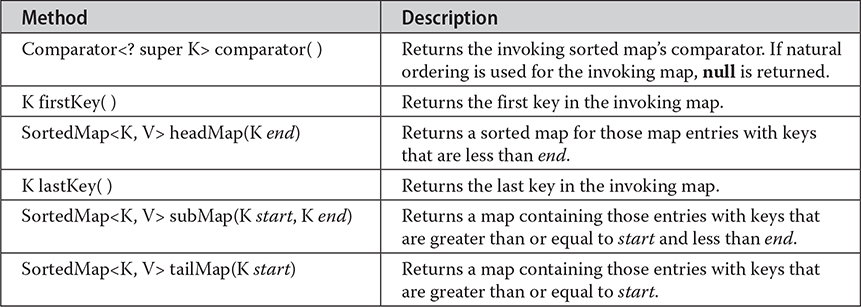
Table 20-14 The Methods Declared by SortedMap
Sorted maps allow very efficient manipulations of submaps (in other words, subsets of a map). To obtain a submap, use headMap(), tailMap(), or subMap(). The submap returned by these methods is backed by the invoking map. Changing one changes the other. To get the first key in the set, call firstKey(). To get the last key, use lastKey().
# The NavigableMap Interface
The NavigableMap interface extends SortedMap and declares the behavior of a map that supports the retrieval of entries based on the closest match to a given key or keys. NavigableMap is a generic interface that has this declaration:
interface NavigableMap<K,V>
Here, K specifies the type of the keys, and V specifies the type of the values associated with the keys. In addition to the methods that it inherits from SortedMap, NavigableMap adds those summarized in Table 20-15. Several methods throw a ClassCastException when an object is incompatible with the keys in the map. A NullPointerException is thrown if an attempt is made to use a null object and null keys are not allowed in the set. An IllegalArgumentException is thrown if an invalid argument is used.
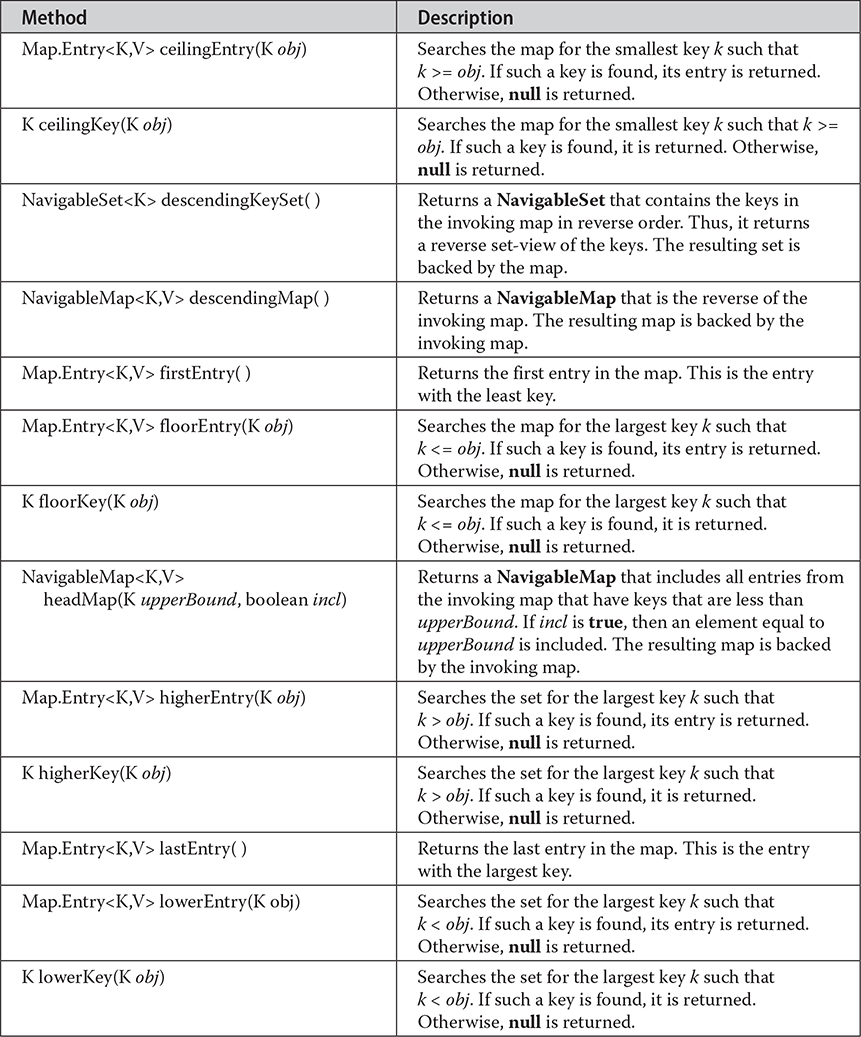
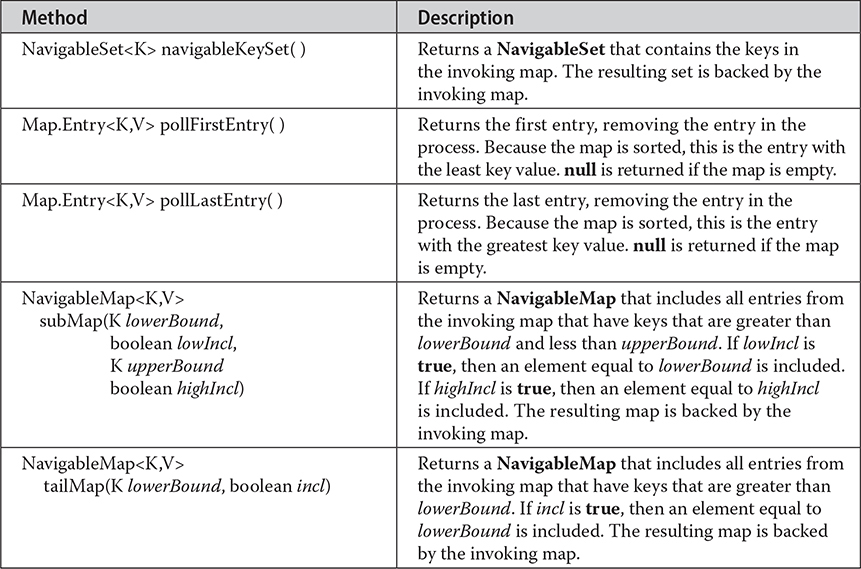
Table 20-15 The Methods Declared by NavigableMap
# The Map.Entry Interface
The Map.Entry interface enables you to work with a map entry. For example, recall that the entrySet() method declared by the Map interface returns a Set containing the map entries. Each of these set elements is a Map.Entry object. Map.Entry is generic and is declared like this:
interface Map.Entry<K, V>
Here, K specifies the type of keys, and V specifies the type of values. Table 20-16 summarizes the non-static methods declared by Map.Entry. It also has three static methods. The first is comparingByKey(), which returns a Comparator that compares entries by key. The second is comparingByValue(), which returns a Comparator that compares entries by value. The third is copyOf(), added by JDK 17. It returns an unmodifiable value-based object that is a copy of the invoking object but is not a part of a map.

Table 20-16 The Non-Static Methods Declared by Map.Entry
# The Map Classes
Several classes provide implementations of the map interfaces. The classes that can be used for maps are summarized here:

Notice that AbstractMap is a superclass for all concrete map implementations.
WeakHashMap implements a map that uses “weak keys,” which allows an element in a map to be garbage-collected when its key is otherwise unused. This class is not discussed further here. The other map classes are described next.
# The HashMap Class
The HashMap class extends AbstractMap and implements the Map interface. It uses a hash table to store the map. This allows the execution time of get() and put() to remain constant even for large sets. HashMap is a generic class that has this declaration:
class HashMap<K, V>
Here, K specifies the type of keys, and V specifies the type of values.
The following constructors are defined:
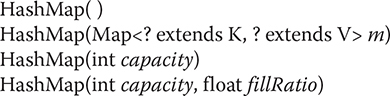
The first form constructs a default hash map. The second form initializes the hash map by using the elements of m. The third form initializes the capacity of the hash map to capacity. The fourth form initializes both the capacity and fill ratio of the hash map by using its arguments. The meaning of capacity and fill ratio is the same as for HashSet, described earlier. The default capacity is 16. The default fill ratio is 0.75.
HashMap implements Map and extends AbstractMap. It adds just one method of its own: the newHashMap() method, added in JDK 19.
You should note that a hash map does not guarantee the order of its elements. Therefore, the order in which elements are added to a hash map is not necessarily the order in which they are read by an iterator.
The following program illustrates HashMap. It maps names to account balances. Notice how a set-view is obtained and used.

Output from this program is shown here (the precise order may vary):

The program begins by creating a hash map and then adds the mapping of names to balances. Next, the contents of the map are displayed by using a set-view, obtained by calling entrySet(). The keys and values are displayed by calling the getKey() and getValue() methods that are defined by Map.Entry. Pay close attention to how the deposit is made into John Doe’s account. The put() method automatically replaces any preexisting value that is associated with the specified key with the new value. Thus, after John Doe’s account is updated, the hash map will still contain just one "John Doe" account.
# The TreeMap Class
The TreeMap class extends AbstractMap and implements the NavigableMap interface. It creates maps stored in a tree structure. A TreeMap provides an efficient means of storing key/value pairs in sorted order and allows rapid retrieval. You should note that, unlike a hash map, a tree map guarantees that its elements will be sorted in ascending key order. TreeMap is a generic class that has this declaration:
class TreeMap<K, V>
Here, K specifies the type of keys, and V specifies the type of values.
The following TreeMap constructors are defined:

The first form constructs an empty tree map that will be sorted by using the natural order of its keys. The second form constructs an empty tree-based map that will be sorted by using the Comparator comp. (Comparators are discussed later in this chapter.) The third form initializes a tree map with the entries from m, which will be sorted by using the natural order of the keys. The fourth form initializes a tree map with the entries from sm, which will be sorted in the same order as sm.
TreeMap has no map methods beyond those specified by the NavigableMap interface and the AbstractMap class.
The following program reworks the preceding example so that it uses TreeMap:


The following is the output from this program:

Notice that TreeMap sorts the keys. However, in this case, they are sorted by first name instead of last name. You can alter this behavior by specifying a comparator when the map is created, as described shortly.
# The LinkedHashMap Class
LinkedHashMap extends HashMap. It maintains a linked list of the entries in the map, in the order in which they were inserted. This allows insertion-order iteration over the map. That is, when iterating through a collection-view of a LinkedHashMap, the elements will be returned in the order in which they were inserted. You can also create a LinkedHashMap that returns its elements in the order in which they were last accessed. This ordering of entries by insertion order, or last access order, is a difference between the preceding TreeMap, which sorts its entries using a Comparator, and this LinkedHashMap. The difference is reflected in the class hierarchy by TreeMap implementing SortedMap and LinkedHashMap the less imposing SequencedMap interface. LinkedHashMap is a generic class that has this declaration:
class LinkedHashMap<K, V>
Here, K specifies the type of keys, and V specifies the type of values.
LinkedHashMap defines the following constructors:
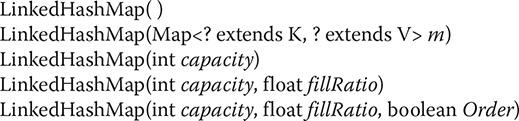
The first form constructs a default LinkedHashMap. The second form initializes the LinkedHashMap with the elements from m. The third form initializes the capacity. The fourth form initializes both capacity and fill ratio. The meaning of capacity and fill ratio are the same as for HashMap. The default capacity is 16. The default ratio is 0.75. The last form allows you to specify whether the elements will be stored in the linked list by insertion order or by order of last access. If Order is true, then access order is used. If Order is false, then insertion order is used.
By implementing the SequencedMap interface, LinkedHashMap implements the methods that allow you to access, add, and remove entries at the start and end of its ordered collection of entries that we saw earlier when we examined the SequencedMap interface and also to produce a version of itself with the entries in reverse order, using the reversed() method. We can see this in action by looking at some code similar to the TreeMap example but using a LinkedHashMap instead.
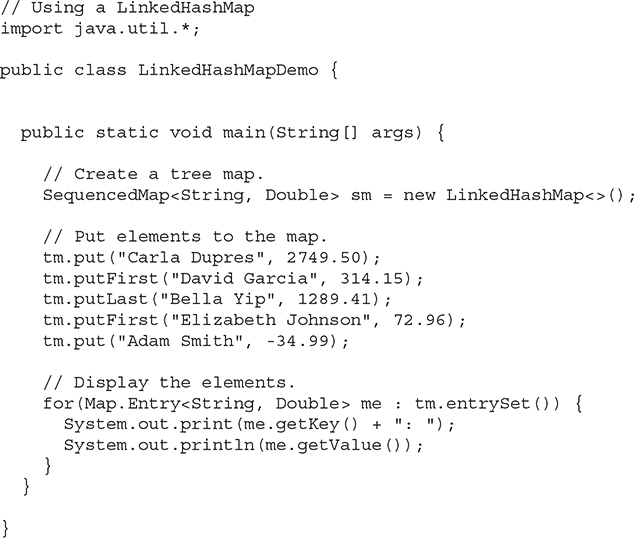
You will notice that this code is using a LinkedHashMap implementation of a SequencedMap type. It’s using the putFirst() and putLast() to carefully insert the entries into particular positions, which consist, as in the TreeMap example, of a name and a Double representing an amount of money representing the balance in a bank account. The output of the program is shown here:

You can see that the order in which the entries are printed out as the code loops through them derives from the position in which the entries were inserted into the map. This is what you would expect since the code uses the default constructor to create an empty map whose encounter order is its insertion order. This is unlike the TreeMap example since the encounter order is reverse alphabetical.
# The IdentityHashMap Class
IdentityHashMap extends AbstractMap and implements the Map interface. It is similar to HashMap except that it uses reference equality when comparing elements. IdentityHashMap is a generic class that has this declaration:
class IdentityHashMap<K, V>
Here, K specifies the type of key, and V specifies the type of value. The API documentation explicitly states that IdentityHashMap is not for general use.
# The EnumMap Class
EnumMap extends AbstractMap and implements Map. It is specifically for use with keys of an enum type. It is a generic class that has this declaration:
class EnumMap<K extends Enum<K>, V>
Here, K specifies the type of key, and V specifies the type of value. Notice that K must extend Enum<K>, which enforces the requirement that the keys must be of an enum type.
EnumMap defines the following constructors:
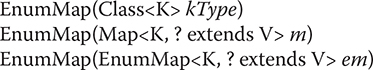
The first constructor creates an empty EnumMap of type kType. The second creates an EnumMap map that contains the same entries as m. The third creates an EnumMap initialized with the values in em.
EnumMap defines no methods of its own.
# Comparators
Both TreeSet and TreeMap store elements in sorted order. However, it is the comparator that defines precisely what “sorted order” means. By default, these classes store their elements by using what Java refers to as “natural ordering,” which is usually the ordering that you would expect (A before B, 1 before 2, and so forth). If you want to order elements a different way, then specify a Comparator when you construct the set or map. Doing so gives you the ability to govern precisely how elements are stored within sorted collections and maps.
Comparator is a generic interface that has this declaration:
interface Comparator<T>
Here, T specifies the type of objects being compared.
Prior to JDK 8, the Comparator interface defined only two methods: compare() and equals(). The compare() method, shown here, compares two elements for order:
int compare(T obj1, T obj2)
obj1 and obj2 are the objects to be compared. Normally, this method returns zero if the objects are equal. It returns a positive value if obj1 is greater than obj2. Otherwise, a negative value is returned. The method can throw a ClassCastException if the types of the objects are not compatible for comparison. By implementing compare(), you can alter the way that objects are ordered. For example, to sort in reverse order, you can create a comparator that reverses the outcome of a comparison.
The equals() method, shown here, tests whether an object equals the invoking comparator:
boolean equals(object obj)
Here, obj is the object to be tested for equality. The method returns true if obj and the invoking object are both Comparator objects and use the same ordering. Otherwise, it returns false. Overriding equals() is not necessary, and most simple comparators will not do so.
For many years, the preceding two methods were the only methods defined by Comparator. With the release of JDK 8, the situation dramatically changed. JDK 8 added significant new functionality to Comparator through the use of default and static interface methods. Each is described here.
You can obtain a comparator that reverses the ordering of the comparator on which it is called by using reversed(), shown here:
default Comparator<T> reversed()
It returns the reverse comparator. For example, assuming a comparator that uses natural ordering for the characters A through Z, a reverse order comparator would put B before A, C before B, and so on.
A method related to reversed() is reverseOrder(), shown next:
static <T extends Comparable<? super T>> Comparator<T> reverseOrder()
It returns a comparator that reverses the natural order of the elements. Conversely, you can obtain a comparator that uses natural ordering by calling the static method naturalOrder(), shown next:
static <T extends Comparable<? super T>> Comparator<T> naturalOrder()
If you want a comparator that can handle null values, use nullsFirst() or nullsLast(), shown here:
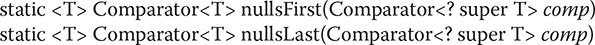
The nullsFirst() method returns a comparator that views null values as less than other values. The nullsLast() method returns a comparator that views null values as greater than other values. In both cases, if the two values being compared are non-null, comp performs the comparison. If comp is passed null, then all non-null values are viewed as equivalent.
Another default method is thenComparing(). It returns a comparator that performs a second comparison when the outcome of the first comparison indicates that the objects being compared are equal. Thus, it can be used to create a “compare by X then compare by Y” sequence. For example, when comparing cities, the first comparison might compare names, with the second comparison comparing states. (Therefore, Springfield, Illinois, would come before Springfield, Missouri, assuming normal, alphabetical order.) The thenComparing() method has three forms. The first, shown here, lets you specify the second comparator by passing an instance of Comparator:
default Comparator<T> thenComparing(Comparator<? super T> thenByComp)
Here, thenByComp specifies the comparator that is called if the first comparison returns equal.
The next versions of thenComparing() let you specify the standard functional interface Function (defined by java.util.function). They are shown here:

In both, getKey refers to function that obtains the next comparison key, which is used if the first comparison returns equal. In the second version, keyComp specifies the comparator used to compare keys. (Here, and in subsequent uses, U specifies the type of the key.)
Comparator also adds the following specialized versions of “then comparing” methods for the primitive types:

In all methods, getKey refers to a function that obtains the next comparison key.
Finally, Comparator has a method called comparing(). It returns a comparator that obtains its comparison key from a function passed to the method. There are two versions of comparing(), shown here:

In both, getKey refers to a function that obtains the next comparison key. In the second version, keyComp specifies the comparator used to compare keys. Comparator also adds the following specialized versions of these methods for the primitive types:

In all methods, getKey refers to a function that obtains the next comparison key.
# Using a Comparator
The following is an example that demonstrates the power of a custom comparator. It implements the compare() method for strings that operates in reverse of normal. Thus, it causes a tree set to be sorted in reverse order.

As the following output shows, the tree is now sorted in reverse order:
F E D C B A
Look closely at the MyComp class, which implements Comparator by implementing compare(). (As explained earlier, overriding equals() is neither necessary nor common. It is also not necessary to override the default methods.) Inside compare(), the String method compareTo() compares the two strings. However, bStr—not aStr—invokes compareTo(). This causes the outcome of the comparison to be reversed.
Although the way in which the reverse order comparator is implemented by the preceding program is perfectly adequate, there is another way to approach a solution. It is now possible to simply call reversed() on a natural-order comparator. It will return an equivalent comparator, except that it runs in reverse. For example, assuming the preceding program, you can rewrite MyComp as a natural-order comparator, as shown here:

Next, you can use the following sequence to create a TreeSet that orders its string elements in reverse:

If you plug this new code into the preceding program, it will produce the same results as before. In this case, there is no advantage gained by using reversed(). However, in cases in which you need to create both a natural-order comparator and a reversed comparator, then using reversed() gives you an easy way to obtain the reverse-order comparator without having to code it explicitly.
It is not actually necessary to create the MyComp class in the preceding examples because a lambda expression can be easily used instead. For example, you can remove the MyComp class entirely and create the string comparator by using this statement:
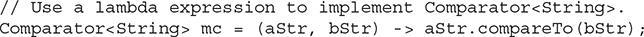
One other point: in this simple example, it would also be possible to specify a reverse comparator via a lambda expression directly in the call to the TreeSet() constructor, as shown here:

By making these changes, the program is substantially shortened, as its final version shown here illustrates:

For a more practical example that uses a custom comparator, the following program is an updated version of the TreeMap program shown earlier that stores account balances. In the previous version, the accounts were sorted by name, but the sorting began with the first name. The following program sorts the accounts by last name. To do so, it uses a comparator that compares the last name of each account. This results in the map being sorted by last name.

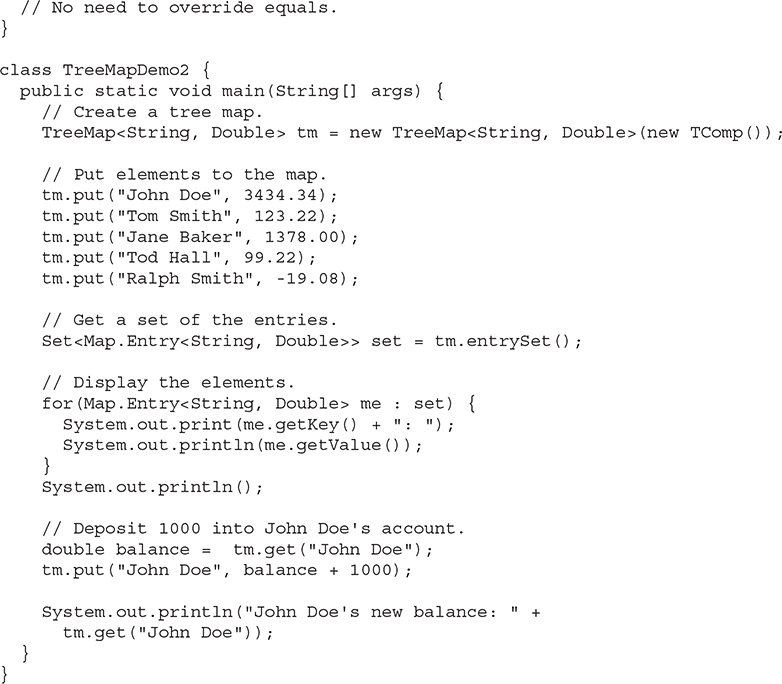
Here is the output; notice that the accounts are now sorted by last name:

The comparator class TComp compares two strings that hold first and last names. It does so by first comparing last names. To do this, it finds the index of the last space in each string and then compares the substrings of each element that begin at that point. In cases where last names are equivalent, the first names are then compared. This yields a tree map that is sorted by last name, and within last name by first name. You can see this because Ralph Smith comes before Tom Smith in the output.
There is another way that you could code the preceding program so the map is sorted by last name and then by first name. This approach uses the thenComparing() method. Recall that thenComparing() lets you specify a second comparator that will be used if the invoking comparator returns equal. This approach is put into action by the following program, which reworks the preceding example to use thenComparing():


This version produces the same output as before. It differs only in how it accomplishes its job. To begin, notice that a comparator called CompLastNames is created. This comparator compares only the last names. A second comparator, called CompThenByFirstName, compares the entire name, starting with the first name. Next, the TreeMap is created by the following sequence:

Here, the primary comparator is compLN. It is an instance of CompLastNames. On it is called thenComparing(), passing in an instance of CompThenByFirstName. The result is assigned to the comparator called compLastThenFirst. This comparator is used to construct the TreeMap, as shown here:
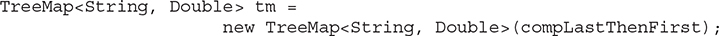
Now, whenever the last names of the items being compared are equal, the entire name, beginning with the first name, is used to order the two. This means that names are ordered based on last name, and within last names, by first names.
One last point: in the interest of clarity, this example explicitly creates two comparator classes called CompLastNames and ThenByFirstNames, but lambda expressions could have been used instead. You might want to try this on your own. Just follow the same general approach described for the CompDemo2 example shown earlier.
# The Collection Algorithms
The Collections Framework defines several algorithms that can be applied to collections and maps. These algorithms are defined as static methods within the Collections class. They are summarized in Table 20-17.
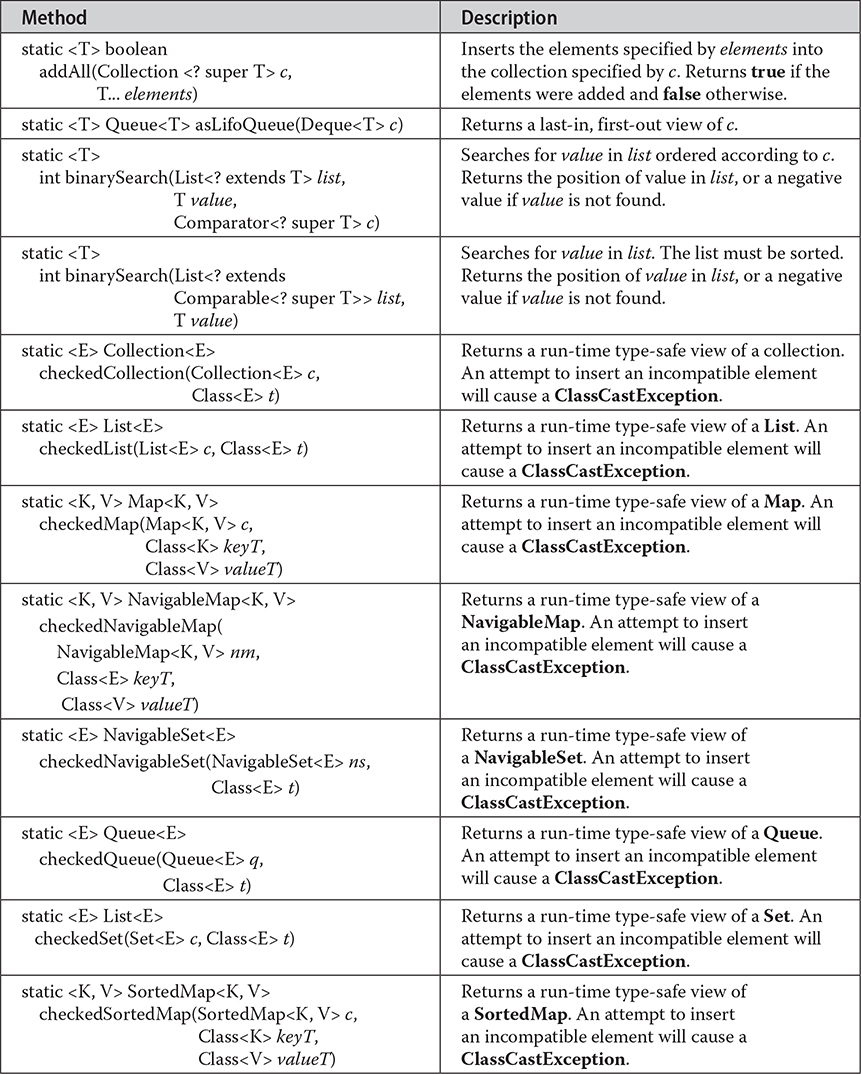
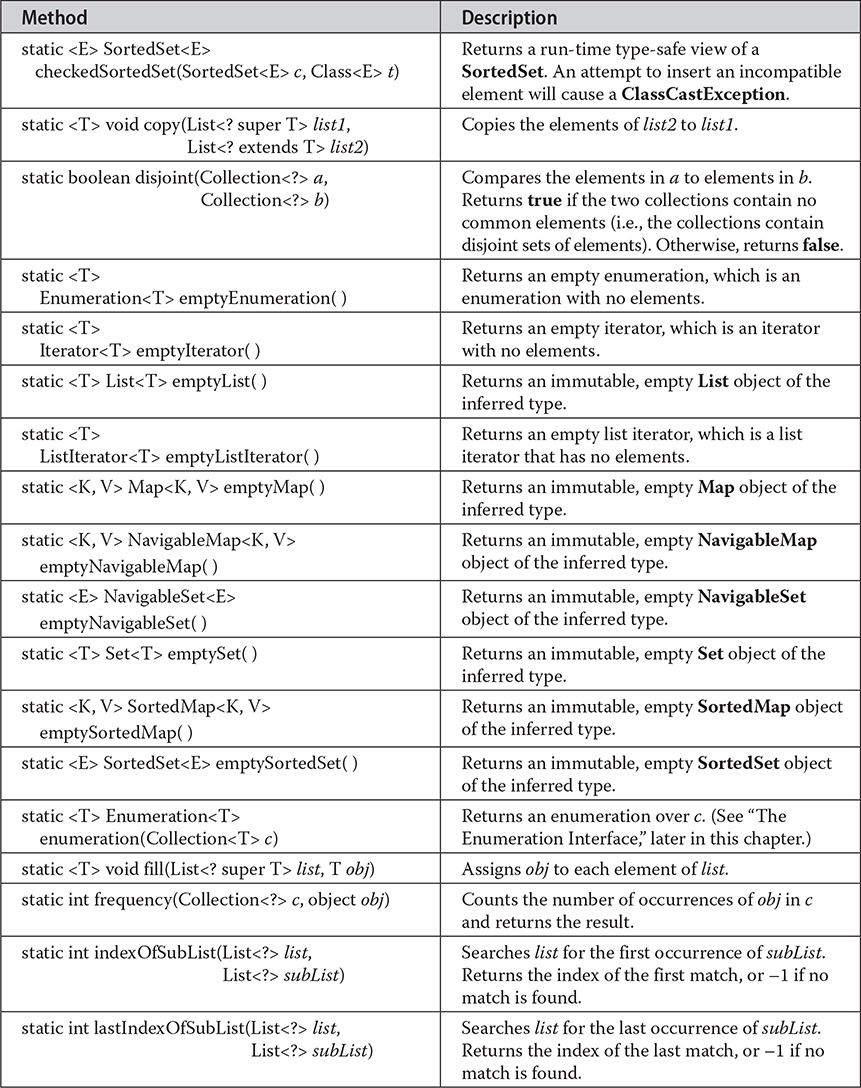
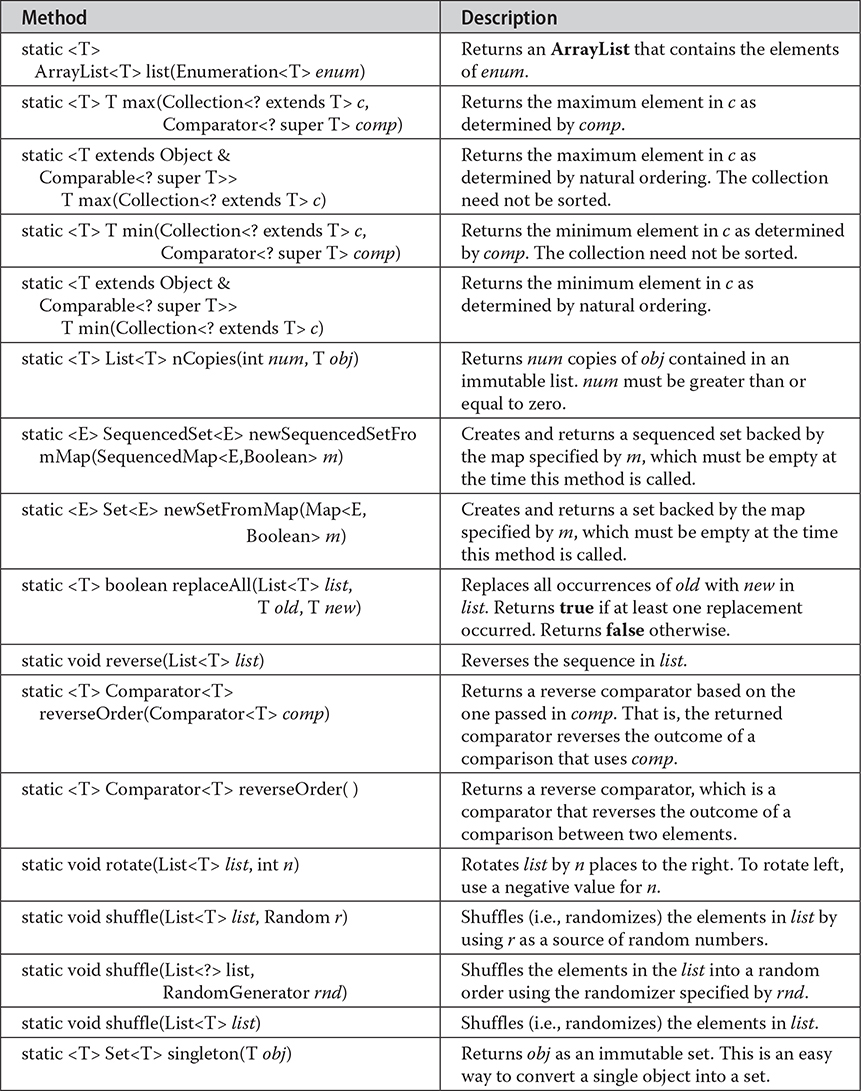
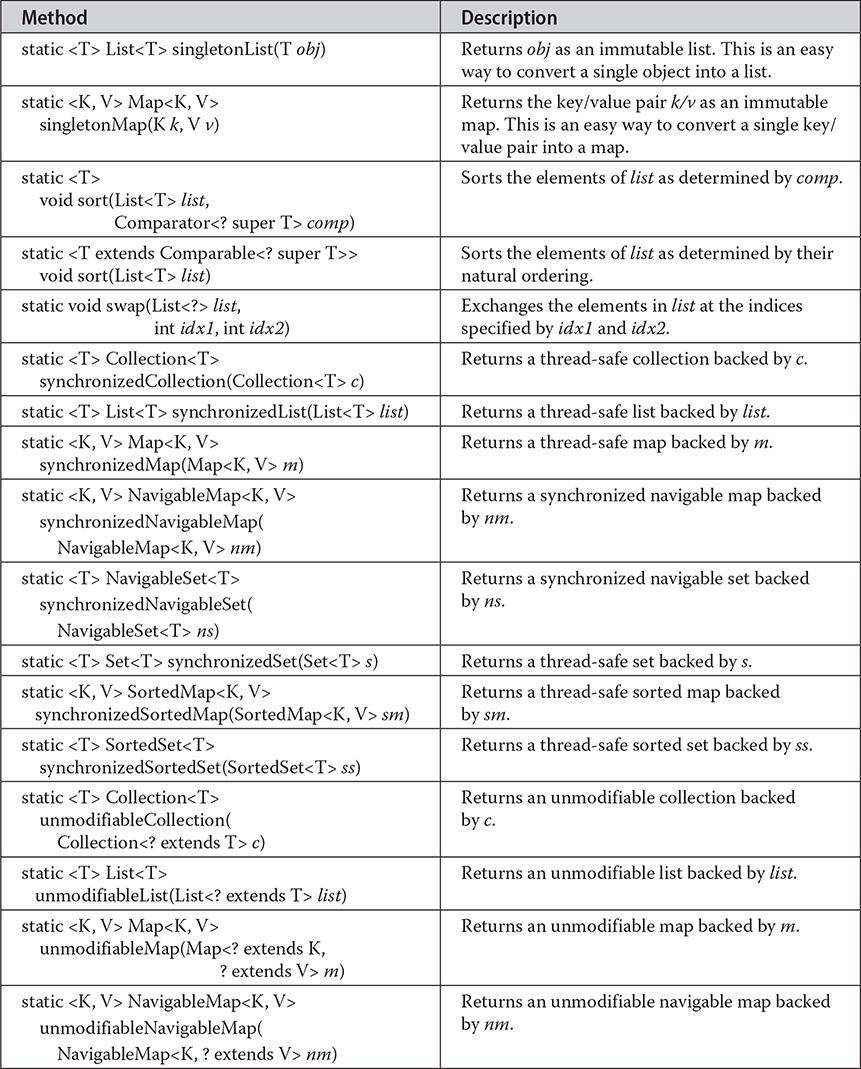
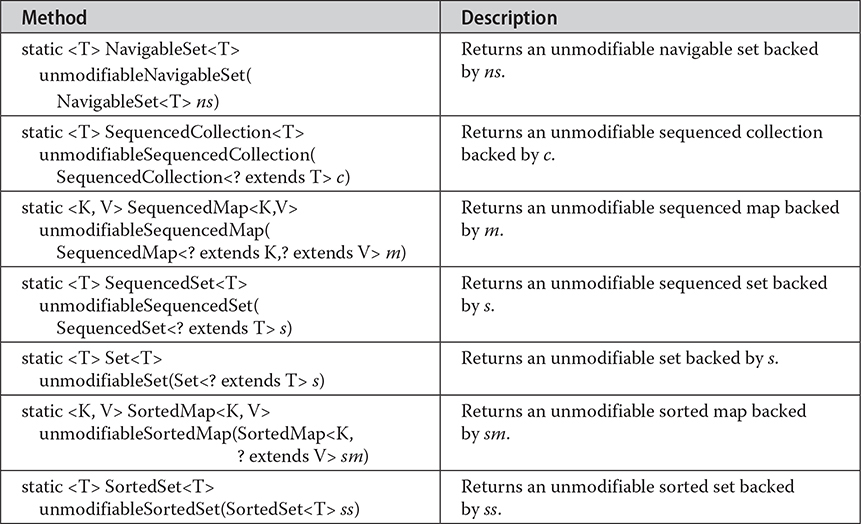
Table 20-17 The Algorithms Defined by Collections
Several of the methods can throw a ClassCastException, which occurs when an attempt is made to compare incompatible types, or an UnsupportedOperationException, which occurs when an attempt is made to modify an unmodifiable collection. Other exceptions are possible, depending on the method.
One thing to pay special attention to is the set of checked methods, such as checkedCollection(), which returns what the API documentation refers to as a “dynamically typesafe view” of a collection. This view is a reference to the collection that monitors insertions into the collection for type compatibility at run time. An attempt to insert an incompatible element will cause a ClassCastException. Using such a view is especially helpful during debugging because it ensures that the collection always contains valid elements. Related methods include checkedSet(), checkedList(), checkedMap(), and so on. They obtain a type-safe view for the indicated collection.
Notice that several methods, such as synchronizedList() and synchronizedSet(), are used to obtain synchronized (thread-safe) copies of the various collections. As a general rule, the standard collections implementations are not synchronized. You must use the synchronization algorithms to provide synchronization. One other point: iterators to synchronized collections must be used within synchronized blocks.
The set of methods that begins with unmodifiable returns views of the various collections that cannot be modified. These will be useful when you want to grant some process read—but not write—capabilities on a collection.
Collections defines three static variables: EMPTY_SET, EMPTY_LIST, and EMPTY_MAP. All are immutable.
The following program demonstrates some of the algorithms. It creates and initializes a linked list. The reverseOrder() method returns a Comparator that reverses the comparison of Integer objects. The list elements are sorted according to this comparator and then are displayed. Next, the list is randomized by calling shuffle(), and then its minimum and maximum values are displayed.

Output from this program is shown here:

Notice that min() and max() operate on the list after it has been shuffled. Neither requires a sorted list for its operation.
# Arrays
The Arrays class provides various static utility methods that are useful when working with arrays. These methods help bridge the gap between collections and arrays. Each method defined by Arrays is examined in this section.
The asList() method returns a List that is backed by a specified array. In other words, both the list and the array refer to the same location. It has the following signature:
static <T> List asList(T... array)
Here, array is the array that contains the data.
The binarySearch() method uses a binary search to find a specified value. This method must be applied to sorted arrays. Here are some of its forms. (Additional forms let you search a subrange):

Here, array is the array to be searched, and value is the value to be located. The last two forms throw a ClassCastException if array contains elements that cannot be compared (for example, Double and StringBuffer) or if value is not compatible with the types in array. In the last form, the Comparator c is used to determine the order of the elements in array. In all cases, if value exists in array, the index of the element is returned. Otherwise, a negative value is returned.
The copyOf() method returns a copy of an array and has the following forms:

The original array is specified by source, and the length of the copy is specified by len. If the copy is longer than source, then the copy is padded with zeros (for numeric arrays), nulls (for object arrays), or false (for boolean arrays). If the copy is shorter than source, then the copy is truncated. In the last form, the type of resultT becomes the type of the array returned. If len is negative, a NegativeArraySizeException is thrown. If source is null, a NullPointerException is thrown. If resultT is incompatible with the type of source, an ArrayStoreException is thrown.
The copyOfRange() method returns a copy of a range within an array and has the following forms:

The original array is specified by source. The range to copy is specified by the indices passed via start and end. The range runs from start to end – 1. If the range is longer than source, then the copy is padded with zeros (for numeric arrays), nulls (for object arrays), or false (for boolean arrays). In the last form, the type of resultT becomes the type of the array returned. If start is negative or greater than the length of source, an ArrayIndexOutOfBoundsException is thrown. If start is greater than end, an IllegalArgumentException is thrown. If source is null, a NullPointerException is thrown. If resultT is incompatible with the type of source, an ArrayStoreException is thrown.
The equals() method returns true if two arrays are equivalent. Otherwise, it returns false. Here are a number of its forms. Several more versions are available that let you specify a range, a generic array type, and/or a comparator.

Here, array1 and array2 are the two arrays that are compared for equality.
The deepEquals() method can be used to determine if two arrays, which might contain nested arrays, are equal. It has this declaration:
static boolean deepEquals(Object[ ] a, Object[ ] b)
It returns true if the arrays passed in a and b contain the same elements. If a and b contain nested arrays, then the contents of those nested arrays are also checked. It returns false if the arrays, or any nested arrays, differ.
The fill() method assigns a value to all elements in an array. In other words, it fills an array with a specified value. The fill() method has two versions. The first version, which has the following forms, fills an entire array:

Here, value is assigned to all elements in array. The second version of the fill() method assigns a value to a subset of an array.
The sort() method sorts an array so that it is arranged in ascending order. The sort() method has two versions. The first version, shown here, sorts the entire array:

Here, array is the array to be sorted. In the last form, c is a Comparator that is used to order the elements of array. The last two forms can throw a ClassCastException if elements of the array being sorted are not comparable. The second version of sort() enables you to specify a range within an array that you want to sort.
One quite powerful method in Arrays is parallelSort() because it sorts, into ascending order, portions of an array in parallel and then merges the results. This approach can greatly speed up sorting times. Like sort(), there are two basic types of parallelSort(), each with several overloads. The first type sorts the entire array. It is shown here:

Here, array is the array to be sorted. In the last form, c is a comparator that is used to order the elements in the array. The last two forms can throw a ClassCastException if the elements of the array being sorted are not comparable. The second version of parallelSort() enables you to specify a range within the array that you want to sort.
Arrays supports spliterators by including the spliterator() method. It has two basic forms. The first type returns a spliterator to an entire array. It is shown here:

Here, array is the array that the spliterator will cycle through. The second version of spliterator() enables you to specify a range to iterate within the array.
Arrays supports the Stream interface by including the stream() method. It has two forms. The first is shown here:

Here, array is the array to which the stream will refer. The second version of stream() enables you to specify a range within the array.
Another two methods are related: setAll() and parallelSetAll(). Both assign values to all of the elements, but parallelSetAll() works in parallel. Here is an example of each:

Several overloads exist for each of these that handle types int, long, and generic.
One of the more intriguing methods defined by Arrays is called parallelPrefix(), and it modifies an array so that each element contains the cumulative result of an operation applied to all previous elements. For example, if the operation is multiplication, then on return, the array elements will contain the values associated with the running product of the original values. It has several overloads. Here is one example:
static void parallelPrefix(double[ ] array, DoubleBinaryOperator func)
Here, array is the array being acted upon, and func specifies the operation applied. (DoubleBinaryOperator is a functional interface defined in java.util.function.) Many other versions are provided, including those that operate on types int, long, and generic, and those that let you specify a range within the array on which to operate.
JDK 9 added three comparison methods to Arrays. They are compare(), compareUnsigned(), and mismatch(). Each has several overloads, and each has versions that let you define a range to compare. Here is a brief description of each. The compare() method compares two arrays. It returns zero if they are the same, a positive value if the first array is greater than the second, and negative if the first array is less than the second. To perform an unsigned comparison of two arrays that hold integer values, use compareUnsigned(). To find the location of the first mismatch between two arrays, use mismatch(). It returns the index of the mismatch, or −1 if the arrays are equivalent.
Arrays also provides toString() and hashCode() for the various types of arrays. In addition, deepToString() and deepHashCode() are provided, which operate effectively on arrays that contain nested arrays.
The following program illustrates how to use some of the methods of the Arrays class:

The following is the output from this program:

# The Legacy Classes and Interfaces
As explained at the start of this chapter, early versions of java.util did not include the Collections Framework. Instead, it defined several classes and an interface that provided an ad hoc method of storing objects. When collections were added (by J2SE 1.2), several of the original classes were reengineered to support the collection interfaces. Thus, they are now technically part of the Collections Framework. However, where a modern collection duplicates the functionality of a legacy class, you will usually want to use the newer collection class.
One other point: none of the modern collection classes described in this chapter are synchronized, but all the legacy classes are synchronized. This distinction may be important in some situations. Of course, you can easily synchronize collections by using one of the algorithms provided by Collections.
The legacy classes defined by java.util are shown here:

There is one legacy interface called Enumeration. The following sections examine Enumeration and each of the legacy classes, in turn.
# The Enumeration Interface
The Enumeration interface defines the methods by which you can enumerate (obtain one at a time) the elements in a collection of objects. This legacy interface has been superseded by Iterator. Although not deprecated, Enumeration is considered obsolete for new code. However, it is used by several methods defined by the legacy classes (such as Vector and Properties) and is used by several other API classes. It was retrofitted for generics by JDK 5. It has this declaration:
interface Enumeration<E>
Here, E specifies the type of element being enumerated.
Enumeration specifies the following two abstract methods:
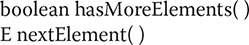
When implemented, hasMoreElements() must return true while there are still more elements to extract, and false when all the elements have been enumerated. nextElement() returns the next object in the enumeration. That is, each call to nextElement() obtains the next object in the enumeration. It throws NoSuchElementException when the enumeration is complete.
JDK 9 added a default method to Enumeration called asIterator(). It is shown here:
default Iterator<E> asIterator()
It returns an iterator to the elements in the enumeration. As such, it provides an easy way to convert an old-style Enumeration into a modern Iterator. Furthermore, if a portion of the elements in the enumeration have already been read prior to calling asIterator(), the returned iterator accesses only the remaining elements.
# Vector
Vector implements a dynamic array. It is similar to ArrayList, but with two differences: Vector is synchronized, and it contains many legacy methods that duplicate the functionality of methods defined by the Collections Framework. With the advent of collections, Vector was reengineered to extend AbstractList and to implement the List interface. With the release of JDK 5, it was retrofitted for generics and reengineered to implement Iterable. This means that Vector is fully compatible with collections, and a Vector can have its contents iterated by the enhanced for loop.
Vector is declared like this:
class Vector<E>
Here, E specifies the type of element that will be stored.
Here are the Vector constructors:

The first form creates a default vector, which has an initial size of 10. The second form creates a vector whose initial capacity is specified by size. The third form creates a vector whose initial capacity is specified by size and whose increment is specified by incr. The increment specifies the number of elements to allocate each time that a vector is resized upward. The fourth form creates a vector that contains the elements of collection c.
All vectors start with an initial capacity. After this initial capacity is reached, the next time that you attempt to store an object in the vector, the vector automatically allocates space for that object plus extra room for additional objects. By allocating more than just the required memory, the vector reduces the number of allocations that must take place as the vector grows. This reduction is important, because allocations are costly in terms of time. The amount of extra space allocated during each reallocation is determined by the increment that you specify when you create the vector. If you don’t specify an increment, the vector’s size is doubled by each allocation cycle.
Vector defines these protected data members:
The increment value is stored in capacityIncrement. The number of elements currently in the vector is stored in elementCount. The array that holds the vector is stored in elementData.
In addition to the collections methods specified by List, Vector defines several legacy methods, which are summarized in Table 20-18.
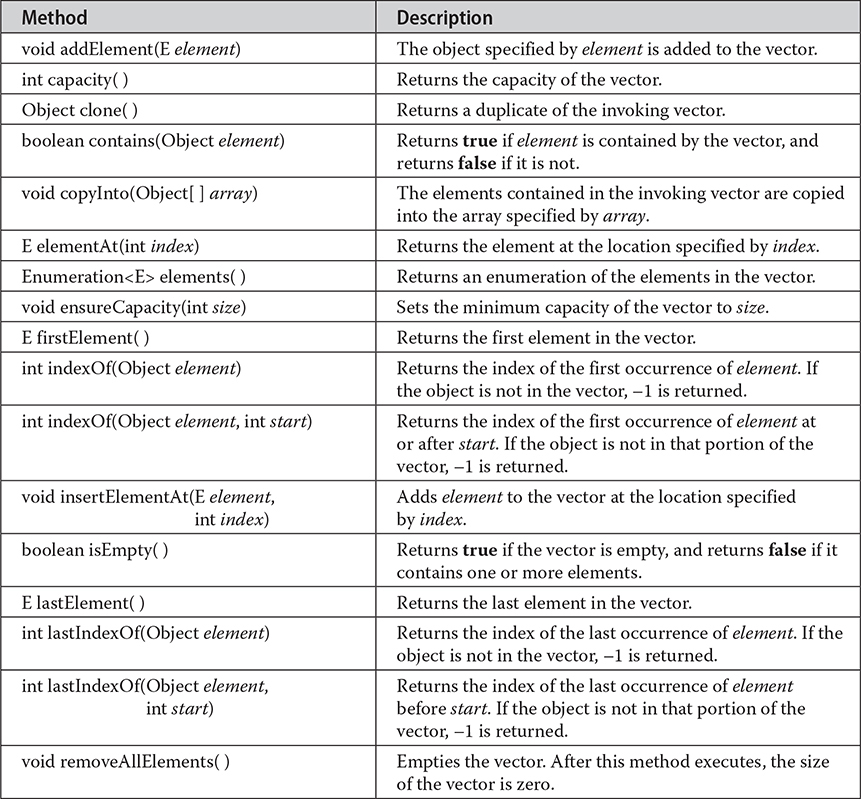
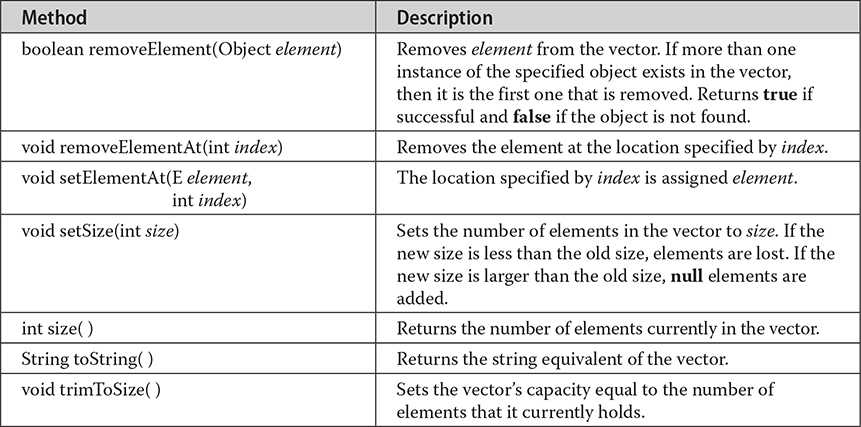
Table 20-18 The Legacy Methods Defined by Vector
Because Vector implements List, you can use a vector just like you use an ArrayList instance. You can also manipulate one using its legacy methods. For example, after you instantiate a Vector, you can add an element to it by calling addElement(). To obtain the element at a specific location, call elementAt(). To obtain the first element in the vector, call firstElement(). To retrieve the last element, call lastElement(). You can obtain the index of an element by using indexOf() and lastIndexOf(). To remove an element, call removeElement() or removeElementAt().
The following program uses a vector to store various types of numeric objects. It demonstrates several of the legacy methods defined by Vector. It also demonstrates the Enumeration interface.


The output from this program is shown here:

Instead of relying on an enumeration to cycle through the objects (as the preceding program does), you can use an iterator. For example, the following iterator-based code can be substituted into the program:

You can also use a for-each for loop to cycle through a Vector, as the following version of the preceding code shows:

Because the Enumeration interface is not recommended for new code, you will usually use an iterator or a for-each for loop to enumerate the contents of a vector. Of course, legacy code will employ Enumeration. Fortunately, enumerations and iterators work in nearly the same manner.
# Stack
Stack is a subclass of Vector that implements a standard last-in, first-out stack. Stack only defines the default constructor, which creates an empty stack. With the release of JDK 5, Stack was retrofitted for generics and is declared as shown here:
class Stack<E>
Here, E specifies the type of element stored in the stack.
Stack includes all the methods defined by Vector and adds several of its own, shown in Table 20-19.
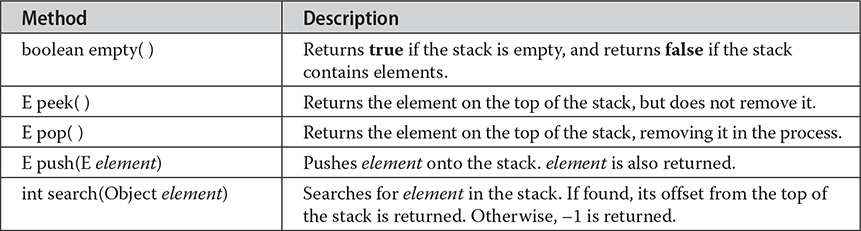
Table 20-19 The Methods Defined by Stack
To put an object on the top of the stack, call push(). To remove and return the top element, call pop(). You can use peek() to return, but not remove, the top object. An EmptyStackException is thrown if you call pop() or peek() when the invoking stack is empty. The empty() method returns true if nothing is on the stack. The search() method determines whether an object exists on the stack and returns the number of pops that are required to bring it to the top of the stack. Here is an example that creates a stack, pushes several Integer objects onto it, and then pops them off again:

The following is the output produced by the program; notice how the exception handler for EmptyStackException is used so that you can gracefully handle a stack underflow:


One other point: although Stack is not deprecated, ArrayDeque is a better choice.
# Dictionary
Dictionary is an abstract class that represents a key/value storage repository and operates much like Map. Given a key and value, you can store the value in a Dictionary object. Once the value is stored, you can retrieve it by using its key. Thus, like a map, a dictionary can be thought of as a list of key/value pairs. Although not currently deprecated, Dictionary is classified as obsolete, because it is fully superseded by Map. However, Dictionary is still in use and thus is discussed here.
With the advent of JDK 5, Dictionary was made generic. It is declared as shown here:
class Dictionary<K, V>
Here, K specifies the type of keys, and V specifies the type of values. The abstract methods defined by Dictionary are listed in Table 20-20.
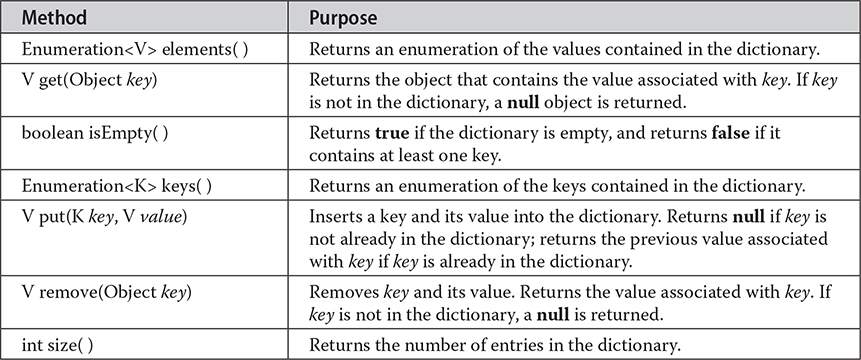
Table 20-20 The Abstract Methods Defined by Dictionary
To add a key and a value, use the put() method. Use get() to retrieve the value of a given key. The keys and values can each be returned as an Enumeration by the keys() and elements() methods, respectively. The size() method returns the number of key/value pairs stored in a dictionary, and isEmpty() returns true when the dictionary is empty. You can use the remove() method to delete a key/value pair.
REMEMBER The Dictionary class is obsolete. You should implement the Map interface to obtain key/value storage functionality.
# Hashtable
Hashtable was part of the original java.util and is a concrete implementation of a Dictionary. However, with the advent of collections, Hashtable was reengineered to also implement the Map interface. Thus, Hashtable is integrated into the Collections Framework. It is similar to HashMap, but is synchronized.
Like HashMap, Hashtable stores key/value pairs in a hash table. However, neither keys nor values can be null. When using a Hashtable, you specify an object that is used as a key, and the value that you want linked to that key. The key is then hashed, and the resulting hash code is used as the index at which the value is stored within the table.
Hashtable was made generic by JDK 5. It is declared like this:
class Hashtable<K, V>
Here, K specifies the type of keys, and V specifies the type of values.
A hash table can only store keys that override the hashCode() and equals() methods that are defined by Object. The hashCode() method must compute and return the hash code for the object. Of course, equals() compares two objects. Fortunately, many of Java’s built-in classes already implement the hashCode() method. For example, a common type of Hashtable uses a String object as the key. String implements both hashCode() and equals().
The Hashtable constructors are shown here:

The first version is the default constructor. The second version creates a hash table that has an initial size specified by size. (The default size is 11.) The third version creates a hash table that has an initial size specified by size and a fill ratio specified by fillRatio. This ratio (also referred to as a load factor) must be between 0.0 and 1.0, and it determines how full the hash table can be before it is resized upward. Specifically, when the number of elements is greater than the capacity of the hash table multiplied by its fill ratio, the hash table is expanded. If you do not specify a fill ratio, then 0.75 is used. Finally, the fourth version creates a hash table that is initialized with the elements in m. The default load factor of 0.75 is used.
In addition to the methods defined by the Map interface, which Hashtable now implements, Hashtable defines the legacy methods listed in Table 20-21. Several methods throw NullPointerException if an attempt is made to use a null key or value.
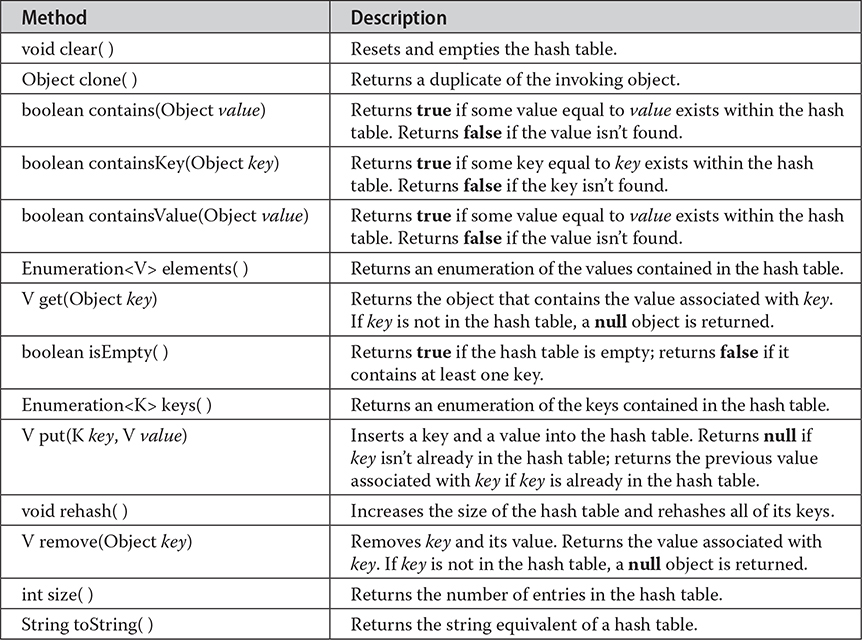
Table 20-21 The Legacy Methods Defined by Hashtable
The following example reworks the bank account program, shown earlier, so that it uses a Hashtable to store the names of bank depositors and their current balances:



The output from this program is shown here:

One important point: Like the map classes, Hashtable does not directly support iterators. Thus, the preceding program uses an enumeration to display the contents of balance. However, you can obtain set-views of the hash table, which permits the use of iterators. To do so, you simply use one of the collection-view methods defined by Map, such as entrySet() or keySet(). For example, you can obtain a set-view of the keys and cycle through them using either an iterator or an enhanced for loop. Here is a reworked version of the program that shows this technique:


# Properties
Properties is a subclass of Hashtable. It is used to maintain lists of values in which the key is a String and the value is also a String. The Properties class is used by some other Java classes. For example, it is the type of object returned by System.getProperties() when obtaining environmental values. Although the Properties class, itself, is not generic, several of its methods are.
Properties defines the following protected volatile instance variable:
Properties defaults;
This variable holds a default property list associated with a Properties object. Properties defines these constructors:

The first version creates a Properties object that has no default values. The second creates an object that uses propDefault for its default values. In both cases, the property list is empty. The third constructor lets you specify an initial capacity for the property list. In all cases, the list will grow as needed.
In addition to the methods that Properties inherits from Hashtable, Properties defines the methods listed in Table 20-22. Properties also contains one deprecated method: save(). This was replaced by store() because save() did not handle errors correctly.
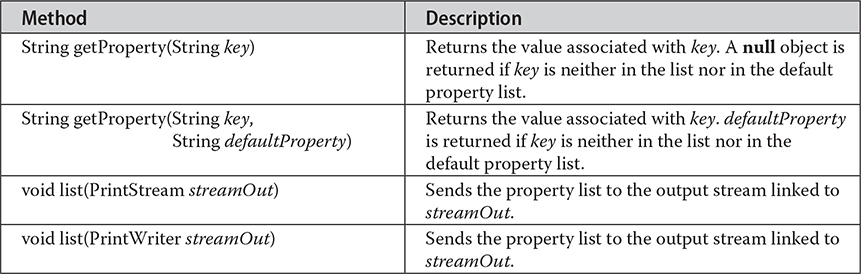
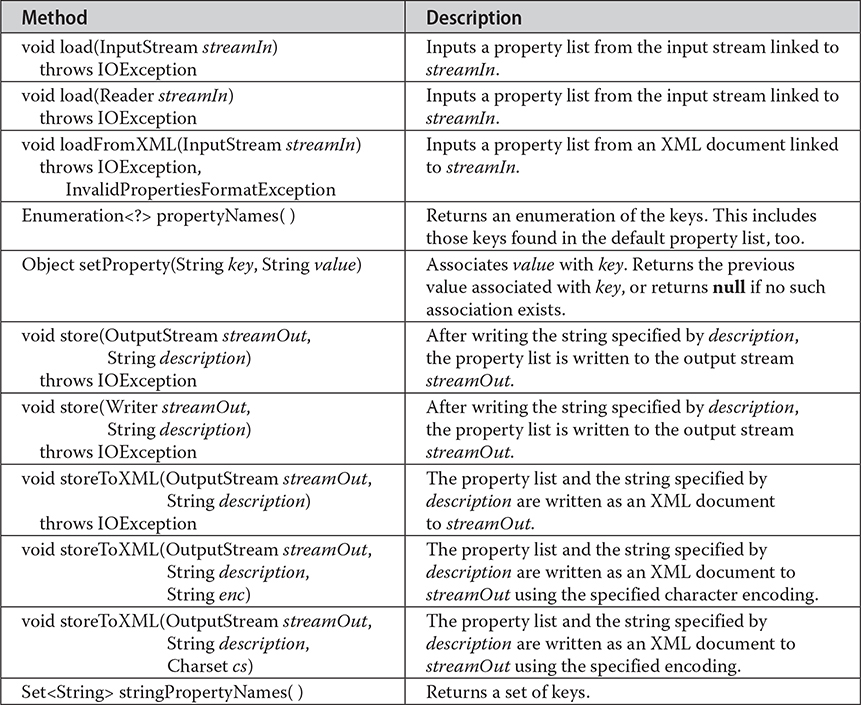
Table 20-22 The Methods Defined by Properties
One useful capability of the Properties class is that you can specify a default property that will be returned if no value is associated with a certain key. For example, a default value can be specified along with the key in the getProperty() method—such as getProperty("name" ,"default value"). If the "name" value is not found, then "default value" is returned. When you construct a Properties object, you can pass another instance of Properties to be used as the default properties for the new instance. In this case, if you call getProperty("foo") on a given Properties object, and "foo" does not exist, Java looks for "foo" in the default Properties object. This allows for arbitrary nesting of levels of default properties.
The following example demonstrates Properties. It creates a property list in which the keys are the names of states and the values are the names of their capitals. Notice that the attempt to find the capital for Florida includes a default value.

The output from this program is shown here:

Since Florida is not in the list, the default value is used.
Although it is perfectly valid to use a default value when you call getProperty(), as the preceding example shows, there is a better way of handling default values for most applications of property lists. For greater flexibility, specify a default property list when constructing a Properties object. The default list will be searched if the desired key is not found in the main list. For example, the following is a slightly reworked version of the preceding program, with a default list of states specified. Now, when Florida is sought, it will be found in the default list:
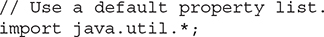

# Using store() and load()
One of the most useful aspects of Properties is that the information contained in a Properties object can be easily stored to or loaded from disk with the store() and load() methods. At any time, you can write a Properties object to a stream or read it back. This makes property lists especially convenient for implementing simple databases. For example, the following program uses a property list to create a simple computerized telephone book that stores names and phone numbers. To find a person’s number, you enter his or her name. The program uses the store() and load() methods to store and retrieve the list. When the program executes, it first tries to load the list from a file called phonebook.dat. If this file exists, the list is loaded. You can then add to the list. If you do, the new list is saved when you terminate the program. Notice how little code is required to implement a small, but functional, computerized phone book.
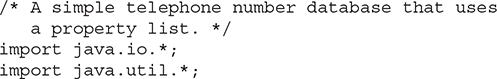


# Parting Thoughts on Collections
The Collections Framework gives you, the programmer, a powerful set of well-engineered solutions to some of programming’s most common tasks. Consider using a collection the next time you need to store and retrieve information. Remember, collections need not be reserved for only the “large jobs,” such as corporate databases, mailing lists, or inventory systems. They are also effective when applied to smaller jobs. For example, a TreeMap might make an excellent collection to hold the directory structure of a set of files. A TreeSet could be quite useful for storing project-management information. Frankly, the types of problems that will benefit from a collections-based solution are limited only by your imagination. One last point: In Chapter 30, the stream API is discussed. Because streams are integrated with collections, consider using a stream when operating on a collection.